需要 Geostatistical Analyst 许可。
如果您有多个数据集并希望使用协同克里金法,则需开发交叉协方差模型。因为存在多个数据集,所以使用下标来追踪变量,例如,Zk(sj ) 表示位置 si 处 kth 数据类型的随机变量 。kth 数据类型和 mth 数据类型之间的交叉协方差函数随后定义为
C km (si,sj) = cov(Zk(si), Zm(sj)).一个非常细微且又容易让人困惑的地方是:C km (si ,sj) 可以是不对称的:C km (si ,sj ) ≠ C mk (si ,sj)(注意下标的变化)。要查看原因,请参见以下示例。假设数据在一个维度中沿线排列,如下所示:

类型 1 和 2 的变量以固定间隔沿线放置,红色粗线表示最高交叉协方差,绿色线表示较小交叉协方差,蓝色细线表示最低交叉协方差,无线则表示 0 交叉协方差。此图显示了 Z1(si ) 和 Z2(sj ) 在 si = sj 时具有最高交叉协方差,交叉协方差会随着 si 和 sj 的距离逐渐拉大而降低。在本例中,C km (si ,sj ) = C mk (si ,sj )。但是,交叉协方差可以“平移”:

请注意,C12(s2,s3) 现在具有最低交叉协方差(蓝色细线),而 C21(s2,s3) 具有最高交叉协方差(红色粗线),因此,这里 C km (si ,sj ) ≠ C mk (si ,sj )。相对于 Z1、Z2 的交叉协方差被平移了 -1 个单位。在两个维度中,如果单击平移参数,Geostatistical Analyst 将对两个数据集之间交叉协方差中的所有平移进行估算。
经验交叉协方差的计算方法如下:
Average [ (z1(si) - 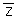 1) (z2(sj) - 2)]
1) (z2(sj) - 2)]
其中 Zk(si) 用于测量 kth 数据集在位置 si
处的值,k 是 kth 数据集的平均值,是对相隔特定距离和角度的所有 si
和 sj 求平均值。对于半变异函数,Geostatistical Analyst 将同时显示交叉协方差的经验模型和拟合的模型。
选择不同的交叉协方差模型、使用复合交叉协方差模型以及选择各向异性都会引起理论模型发生变化。可通过查看模型与经验值的拟合程度对模型进行初步选择。更改步长大小和步长数以及添加平移都会改变经验交叉协方差表面,从而引起理论模型发生相应变化。Geostatistical Analyst 将对默认值进行计算,但您应自由尝试其他值并使用验证和交叉验证来选择最佳模型。