Zusammenfassung
Dieses Werkzeug erstellt auf der Basis von Ereignispunkten oder gewichteten Features (Punkte oder Polygone) mithilfe der Anselin Local Morans I-Statistik eine Karte von statistisch signifikanten Hot-Spots, Cold-Spots und räumlichen Ausreißern. Es wertet die Eigenschaften der Eingabe-Feature-Class aus, um optimale Ergebnisse zu erzeugen.
Weitere Informationen zur Funktionsweise der optimierten Ausreißeranalyse
Abbildung
Verwendung
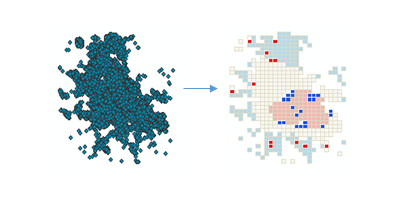
Dieses Werkzeug identifiziert statistisch signifikante räumliche Cluster mit hohen Werten (Hot-Spots) und niedrigen Werten (Cold-Spots) sowie hohe und niedrige Ausreißer in Ihrem Dataset. Es fasst Ereignisdaten zusammen, identifiziert einen geeigneten Analysemaßstab und korrigiert Mehrfachtests und räumliche Abhängigkeit. Dieses Werkzeug fragt Ihre Daten ab, um Einstellungen zu ermitteln, die optimale Cluster- und Ausreißeranalyseergebnisse liefern. Für eine vollständige Kontrolle über diese Einstellungen verwenden Sie stattdessen das Werkzeug Cluster- und Ausreißeranalyse.
Die berechneten Einstellungen zur Erzeugung optimaler Cluster- und Ausreißeranalyseergebnisse werden im Ereignisfenster angezeigt. Die zugehörigen Workflows und Algorithmen werden unter Funktionsweise der optimierten Ausreißeranalyse erläutert.
Mit diesem Werkzeug wird eine neue Ausgabe-Feature-Class mit einem Local Morans I-Index (LMiIndex), Z-Wert, Pseudo-p-Wert und Cluster-/Ausreißer-Typ (COType) anhand der folgenden Attribute für jedes Feature in der Eingabe-Feature-Class erstellt. Es enthält auch das Feld (N Nachbarn) mit der Anzahl der Nachbarn, die jedes Feature in seine Berechnungen eingeschlossen hat.
Das Feld COTypeidentifiziert statistisch signifikante hohe und niedrige Cluster (HH und LL) sowie hohe und niedrige Ausreißer (HL und LH), die mithilfe der FDR-Korrekturmethode (False Discovery Rate) für Mehrfachtests und räumliche Abhängigkeit korrigiert werden.
Die Z-Werte und p-Werte sind Werte von statistischer Bedeutung, die Aufschluss darüber geben, ob Sie die NULL-Hypothese auf Feature-Ebene ablehnen können oder nicht. Genau genommen geben Sie an, ob die scheinbare Ähnlichkeit (eine räumliche Cluster-Bildung von hohen oder niedrigen Werten) oder die Unterschiede (ein räumlicher Ausreißer) auffälliger sind als bei einer zufälligen Verteilung. Die p-Werte und Z-Werte in der Ausgabe-Feature-Class spiegeln keine FDR-Korrekturen (False Discovery Rate) wider. Weitere Informationen zu Z-Werten und p-Werten finden Sie unter Was ist ein Z-Wert? Was ist ein p-Wert?
Ein hoher positiver Z-Wert für ein Feature deutet darauf hin, dass die umgebenden Features ähnliche Werte (hohe oder niedrige Werte) aufweisen. Das COType-Feld in der Ausgabe-Feature-Class ist HH für einen statistisch signifikanten Cluster mit hohen Werten und LL für ein statistisch signifikantes Cluster mit niedrigen Werten.
Ein niedriger negativer Z-Wert (beispielsweise -3,96) für ein Feature deutet auf einen statistisch signifikanten Ausreißer räumlicher Daten hin. Das COType-Feld in der Ausgabe-Feature-Class gibt an, ob das Feature einen hohen Wert aufweist und von Features mit niedrigen Werten (HL) umgeben ist, oder ob das Feature einen niedrigen Wert aufweist und von Features mit hohen Werten (LH) umgeben ist.
Das COType-Feld gibt immer statistisch signifikante Cluster und Ausreißer basierend auf einem FDR-korrigierten Konfidenzniveau von 95 Prozent an. Nur statistisch signifikante Features verfügen über Werte für das COType-Feld.
Wenn die Eingabe-Feature-Class nicht projiziert ist (d. h., wenn Koordinaten in Grad, Minuten und Sekunden angegeben werden) oder als Ausgabe-Koordinatensystem ein geographisches Koordinatensystem festgelegt wurde, werden Entfernungen mit Sehnenmesswerten berechnet. Sehnenentfernungsmesswerte werden verwendet, weil sie schnell berechnet werden können und ausgezeichnete Schätzung von echten geodätischen Entfernungen zulassen, zumindest für Punkte innerhalb von 30 Grad voneinander. Sehnenentfernungen basieren auf einem abgeplatteten Sphäroid. Im Fall von zwei beliebigen Punkten auf der Erdoberfläche ist die Sehnenentfernung zwischen diesen die Länge einer Linie, die durch die dreidimensionale Erde führt, um diese beiden Punkte zu verbinden. Sehnenentfernungen werden in Metern angegeben.
Bei den Eingabe-Features kann es sich um Punkte oder Polygone handeln. Für Polygone ist ein Analysefeld erforderlich.
Wenn Sie ein Analysefeld bereitstellen, sollte es eine Reihe von Werten enthalten. Für diese Statistikberechnung ist es erforderlich, dass nicht alle Variablen den gleichen Wert aufweisen; eine Berechnung ist z. B. nicht möglich, wenn alle Eingabewerte 1 lauten.
Mit einem Analysefeld ist dieses Werkzeug für alle Daten (Punkte oder Polygone) einschließlich Referenzdaten geeignet. Selbst bei Oversampling kann dieses Werkzeug effektiv und zuverlässig eingesetzt werden. Bei vielen Features (Oversampling) verfügt das Werkzeug über mehr Informationen, um genaue und zuverlässige Ergebnisse zu berechnen. Bei wenigen Features (Undersampling) versucht das Werkzeug dennoch, genaue und zuverlässige Ergebnisse zu erzeugen. Es gibt jedoch weniger Informationen, die verarbeitet werden können.
Bei Punktdaten gilt das Interesse manchmal der Analyse von Werten, die mit einzelnen Punkt-Features verknüpft sind, sodass ein Analysefeld bereitgestellt wird. In anderen Fällen möchten Sie nur das räumliche Muster (Cluster-Bildung) der Punktpositionen oder Punktereignisse ermitteln. Die Entscheidung, ob ein Analysefeld bereitgestellt werden soll oder nicht, hängt von der Frage ab, die Sie stellen.
- Die Analyse von Punkt-Features mit einem Analysefeld ermöglicht die Beantwortung von Fragen wie: Wo bilden hohe und niedrige Werte Cluster?
- Das ausgewählte Analysefeld kann Folgendes darstellen:
- Zählwerte (wie die Anzahl der Verkehrsunfälle an Kreuzungen)
- Verhältniswerte (wie die Arbeitslosigkeit in einem Ort, wobei der Ort durch ein Punkt-Feature dargestellt wird)
- Durchschnittswerte (wie die Durchschnittspunktzahl eines Mathematiktests in verschiedenen Schulen)
- Indizes (wie die Bewertung der Kundenzufriedenheit bei Autohändlern in einem Land)
- Wenn Punkt-Features analysiert werden, ohne dass ein Analysefeld zur Verfügung steht, können Sie ermitteln, wo die Punkt-Cluster-Bildung ungewöhnlich (statistisch signifikant) ausgeprägt oder gering ist. Dieser Analysetyp ermöglicht die Beantwortung von Fragen wie: Wo gibt es viele Punkte? Wo gibt es sehr wenig Punkte?
Wenn Sie kein Analysefeld angeben, aggregiert das Werkzeug die Punkte, um die Anzahl von Punkten zu ermitteln und als Analysefeld zu verwenden. Hierzu sind drei Aggregationsschemas denkbar:
- Für COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS und COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS wird eine geeignete Polygon-Zellengröße berechnet und zum Erstellen eines Netzes oder Hexagonpolygonnetzes verwendet, das anschließend über die Ereignispunkte positioniert wird. Zudem werden die Punkte innerhalb jeder Polygonzelle gezählt. Wenn der Feature-Layer Umgebende Polygone, die den räumlichen Geltungsbereich für Ereignisse definieren nicht bereitgestellt wird, werden die Zellen mit 0 Punkten entfernt und nur die verbleibenden Zellen analysiert. Wenn ein Feature-Layer für umgebende Polygone bereitgestellt wird, werden alle Zellen, die sich innerhalb der umgebenden Polygone befinden, beibehalten und analysiert. Die Punktanzahl der einzelnen Polygonzellen wird als Analysefeld verwendet.
- Für COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS und COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS müssen Sie den Feature-Layer Polygone zum Aggregieren von Ereignissen in Anzahlwerte bereitstellen. Die Punktereignisse innerhalb der einzelnen Polygone werden gezählt und diese Polygone mit den zugehörigen Anzahlwerten werden analysiert. COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS ist eine geeignete Aggregationsstrategie, wenn Punkte mit Verwaltungseinheiten wie Bezirken, Landkreisen oder Schulbezirken verknüpft sind. Sie können diese Option auch dann verwenden, wenn das Untersuchungsgebiet für mehrere Analysen unverändert bleiben soll, um bessere Vergleiche anstellen zu können.
- Für SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS wird eine Fangentfernung berechnet und zum Aggregieren nahe gelegener Ereignispunkte verwendet. Jedem aggregierten Punkt wird eine Anzahl zugewiesen, die die Anzahl der zusammen gefangenen Ereignisse widerspiegelt. Die aggregierten Punkte werden anschließend mit der Ereignisanzahl analysiert, die als Analysefeld dient. Die Option SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS ist eine geeignete Aggregationsstrategie, wenn Sie über viele lagegleiche oder fast lagegleiche Punkte verfügen und Aspekte des räumlichen Musters der ursprünglichen Punktdaten beibehalten möchten. In vielen Fällen können Sie sowohl SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS als auch COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS testen, um zu ermitteln, welches Ergebnis das räumliche Muster der ursprünglichen Punktdaten am besten widerspiegelt. Netz- und Hexagon-Lösungen können Punkt-Ereignis-Cluster künstlich trennen, die Ausgabe ist jedoch möglicherweise leichter zu interpretieren als eine Ausgabe mit gewichteten Punkten.
Wenn Sie COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS oder COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS als Methode für die Aggregation der Ereignisdaten auswählen, können Sie optional den Feature-Layer Umgebende Polygone, die den räumlichen Geltungsbereich für Ereignisse definieren angeben. Wenn keine umgebenden Polygone bereitgestellt werden, kann das Werkzeug nicht erkennen, ob eine Position ohne Ereignis den Wert 0 haben sollte, um anzugeben, dass ein Ereignis an dieser Position möglich, jedoch nicht aufgetreten ist, oder ob die Position aus der Analyse entfernt werden sollte, weil Ereignisse an dieser Position niemals auftreten würden. Demzufolge werden nur Zellen mit mindestens einem Ereignis für die Analyse beibehalten, wenn keine umgebenden Polygone bereitgestellt werden. Wenn dieses Verhalten nicht gewünscht ist, können Sie den Feature-Layer Umgebende Polygone, die den räumlichen Geltungsbereich für Ereignisse definieren, bereitstellen, um sicherzustellen, dass alle Positionen innerhalb der umgebenden Polygone beibehalten werden. Netz- oder Hexagonzellen, denen keine Ereignisse zugrunde liegen, wird die Ereigniszahl 0 zugewiesen.
Jedes Ereignis außerhalb von Umgebende Polygone, die den räumlichen Geltungsbereich für Ereignisse definieren oder Polygone zum Aggregieren von Ereignissen in Anzahlwerte wird aus der Analyse ausgeschlossen.
Der Parameter Performance-Anpassung gibt an, wie viele Permutationen in der Analyse verwendet werden. Bei der Auswahl der Anzahl von Permutationen muss zwischen Genauigkeit und erhöhter Verarbeitungszeit abgewogen werden. Eine Erhöhung der Anzahl von Permutationen führt zu einer höheren Genauigkeit, da die Spanne möglicher Werte für den Pseudo-p-Wert zunimmt.
Permutationen werden verwendet, um zu bestimmen, wie hoch die Wahrscheinlichkeit ist, die analysierten Werte tatsächlich mit der vorhandenen räumlichen Verteilung aufzufinden. Für jede Permutation werden die Nachbarschaftswerte um jedes Feature zufällig neu angeordnet und der Local Morans I-Wert berechnet. Das Ergebnis ist eine Referenzverteilung von Werten, die daraufhin mit den tatsächlich beobachteten Morans I-Werten verglichen wird, um zu bestimmen, mit welcher Wahrscheinlichkeit der beobachtete Wert in der zufälligen Verteilung gefunden werden kann. Die Standardeinstellung liegt bei 199 Permutationen. Die Verteilung der Zufallsstichproben und damit die Genauigkeit des Pseudo-p-Wertes wird jedoch durch eine zunehmende Anzahl von Permutationen verbessert.
Das Werkzeug berechnet den optimalen Analysemaßstab basierend auf den Eigenschaften Ihrer Daten. Sie können den Analysemaßstab auch über den Parameter Entfernungsband in Einstellungen überschreiben festlegen. Für Features ohne Nachbarn mit dieser Entfernung wird das Entfernungsband angepasst, damit jedes Feature mindestens einen Nachbar hat.
Wenn das Werkzeug nicht zur Auswahl optimaler Standardwerte für Gitterzellengröße und Analysemaßstab verwendet werden soll, kann Einstellungen überschreiben verwendet werden, um die Zellengröße oder das Entfernungsband für die Analyse festzulegen.
Mit der Option Zellengröße können Sie die Größe des Gitter festlegen, das für die Aggregierung Ihrer Punktdaten verwendet wurde. Sie können beispielsweise festlegen, dass jede Zelle im Netzgitter die Größe 50 x 50 Meter haben sollte. Beim Aggregieren in Hexagone entspricht die Zellengröße der Höhe jedes Hexagons und die Breite des resultierenden Hexagons der doppelten Höhe dividiert durch die Quadratwurzel von 3.

Sie sollten die Werkzeuge Räumliche Gewichtungsmatrix erstellen oder Räumliche Gewichtungsmatrix erstellen und Cluster- und Ausreißeranalyse verwenden, wenn Sie Raum-Zeit-Hot-Spots ermitteln möchten. Weitere Informationen zur Raum-Zeit-Cluster-Analyse finden Sie unter dem Thema Space Time Pattern Mining oder in der Dokumentation zu Raum-Zeit-Cluster-Analysen.
-
Sie können Karten-Layer verwenden, um die Eingabe-Feature-Class zu definieren. Beim Verwenden eines Layers mit einer Auswahl sind nur die ausgewählten Features in der Analyse enthalten.
-
Der Ausgabe-Feature-Layer wird dem Inhaltsverzeichnis automatisch mit Standard-Rendering für das COType-Feld hinzugefügt. Das Rendering wird durch eine Layer-Datei in <ArcGIS>\Desktop10.x\ArcToolbox\Templates\Layers definiert. Sie können das Standard-Rendering nach Bedarf erneut anwenden, indem Sie die Vorlagen-Layer-Symbolisierung importieren.
Syntax
OptimizedOutlierAnalysis_stats (Input_Features, Output_Features, {Analysis_Field}, {Incident_Data_Aggregation_Method}, {Bounding_Polygons_Defining_Where_Incidents_Are_Possible}, {Polygons_For_Aggregating_Incidents_Into_Counts}, {Performance_Adjustment}, {Cell_Size}, {Distance_Band})| Parameter | Erläuterung | Datentyp |
Input_Features | Die Punkt- oder Polygon-Feature-Class, für die die Cluster- und Ausreißeranalyse durchgeführt wird. | Feature Layer |
Output_Features | Die Ausgabe-Feature-Class zum Empfangen der Ergebnisfelder. | Feature Class |
Analysis_Field (optional) | Das Zahlenfeld (Anzahl von Ereignissen, Kriminalitätsraten, Testergebnisse usw.), das ausgewertet werden soll. | Field |
Incident_Data_Aggregation_Method (optional) | Die Aggregationsmethode, die zum Erstellen gewichteter Features für die Analyse aus Ereignispunktdaten verwendet werden soll.
| String |
Bounding_Polygons_Defining_Where_Incidents_Are_Possible (optional) | Eine Polygon-Feature-Class, die definiert, wo die Ereignis-Input_Features möglicherweise auftreten könnten. | Feature Layer |
Polygons_For_Aggregating_Incidents_Into_Counts (optional) | Die Polygone, die zum Aggregieren der Ereignis-Input_Features verwendet werden, um eine Ereignisanzahl für jedes Polygon-Feature zu ermitteln. | Feature Layer |
Performance_Adjustment (optional) | Diese Analyse verwendet Permutationen, um eine Referenzverteilung zu erstellen. Bei der Auswahl der Anzahl von Permutationen muss zwischen Genauigkeit und erhöhter Verarbeitungszeit abgewogen werden. Legen Sie Ihre Präferenz für Geschwindigkeit im Vergleich zu Genauigkeit fest. Robuste und präzise Ergebnisse erfordern mehr Zeit zur Berechnung.
| String |
Cell_Size (optional) | Die Größe der Gitterzellen, die zum Aggregieren der Input_Features verwendet werden. Beim Aggregieren in ein Hexagongitter wird diese Entfernung als Höhe zum Konstruieren der Polygone mit Hexagonen verwendet. Dieses Werkzeug unterstützt nur Kilometer, Meter, Meilen und Fuß. | Linear Unit |
Distance_Band (optional) | Die räumliche Ausdehnung der Analysenachbarschaft. Anhand dieses Wertes wird bestimmt, welche Features zusammen analysiert werden, um lokale Cluster-Bildung zu bewerten. Dieses Werkzeug unterstützt nur Kilometer, Meter, Meilen und Fuß. | Linear Unit |
Codebeispiel
OptimizedOutlierAnalysis – Beispiel 1 (Python-Fenster)
Das folgende Skript veranschaulicht, wie das Werkzeug OptimizedOutlierAnalysis im Python-Fenster verwendet wird.
import arcpy
arcpy.env.workspace = r"C:\OOA"
arcpy.OptimizedOutlierAnalysis_stats("911Count.shp", "911OptimizedOutlier.shp", "#", "SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS", "#", "#", "BALANCED_499", "#", "#")
OptimizedOutlierAnalysis – Beispiel 2 (eigenständiges Python-Skript)
Das folgende eigenständige Python-Skript veranschaulicht, wie Sie das Werkzeug OptimizedOutlierAnalysis verwenden.
# Analyze the spatial distribution of 911 calls in a metropolitan area
# Import system modules
import arcpy
# Set property to overwrite existing output, by default
arcpy.env.overwriteOutput = True
# Local variables...
workspace = r"C:\OOA\data.gdb"
try:
# Set the current workspace (to avoid having to specify the full path to the feature classes each time)
arcpy.env.workspace = workspace
# Create a polygon that defines where incidents are possible
# Process: Minimum Bounding Geometry of 911 call data
arcpy.MinimumBoundingGeometry_management("Calls911", "Calls911_MBG", "CONVEX_HULL", "ALL",
"#", "NO_MBG_FIELDS")
# Optimized Outlier Analysis of 911 call data using fishnet aggregation method with a bounding polygon of 911 call data
# Process: Optimized Outlier Analysis
ooa = arcpy.OptimizedOutlierAnalysis_stats("Calls911", "Calls911_ohsaFishnet", "#", "COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS",
"Calls911_MBG", "#", "BALANCED_499", , "#", "#")
except arcpy.ExecuteError:
# If any error occurred when running the tool, print the messages
print(arcpy.GetMessages())
Umgebungen
Lizenzinformationen
- ArcGIS Desktop Basic: Ja
- ArcGIS Desktop Standard: Ja
- ArcGIS Desktop Advanced: Ja
Verwandte Themen
- Modellierung von räumlichen Beziehungen
- Was ist ein Z-Wert? Was ist ein p-Wert?
- Räumliche Gewichtungen
- Überblick über das Toolset "Cluster-Zuordnung"
- Räumliche Autokorrelation (Morans I)
- Funktionsweise der optimierten Ausreißeranalyse
- Cluster- und Ausreißeranalyse (Anselin Local Morans I)
- Hot-Spot-Analyse (Getis-Ord Gi*)
- Optimierte Hot-Spot-Analyse