La herramienta Crear cubo de espacio-tiempo agregando puntos toma entidades de punto con marca de hora y las estructura en un cubo de datos netCDF agregando los puntos en bins de espacio-tiempo. Los puntos se cuentan dentro de cada bin, se calculan todas las estadísticas del Campo de resumen y la tendencia para los valores de bin en cada ubicación a lo largo del tiempo se mide mediante la estadística de Mann-Kendall. Esta herramienta se suele utilizar para crear el cubo de entrada necesario para realizar minerías de patrones de espacio-tiempo más detalladas, pero también se puede utilizar para examinar tendencias de series temporales en las áreas de estudio.
Interpretar los resultados
La salida de esta herramienta es una representación netCDF de los puntos de entrada. Puede visualizar los datos del recuento de puntos del cubo en 2D o en 3D con ArcGIS Pro. Además del archivo netCDF, se escriben mensajes en los que se resumen las dimensiones y el contenido del cubo de espacio-tiempo en la ventana Resultados. Haga clic con el botón derecho del ratón en la entrada Mensajes de la ventana Resultados y seleccione Ver para mostrar los resultados en el cuadro de diálogo Mensaje.

La estructura del cubo tendrá filas, columnas y períodos de tiempo. SI multiplica el número de filas por el número de columnas y por el número de períodos de tiempo, obtendrá el número total de bins del cubo. Las filas y las columnas determinan la extensión espacial del cubo, mientras que los períodos de tiempo determinan la extensión temporal.

En la mayoría de análisis solo se incluirán las ubicaciones que tengan datos para un intervalo de período de tiempo como mínimo, aunque se analizarán para todos los períodos. Cuando calcula el recuento de puntos, se da por hecho que el recuento es cero cuando un bin no tiene puntos, pero la ubicación asociada ha tenido al menos un punto para un intervalo de período de tiempo como mínimo. La información sobre el porcentaje de ceros asociado a las ubicaciones que tienen datos para un intervalo de período de tiempo como mínimo viene indicada en los mensajes como escasez. Cuando se calculan los valores para los Campos de resumen, el parámetro Rellenar bins vacíos con determina cómo se rellenarán los bins sin puntos. Todos los bins que no se pueden rellenar según los criterios de estimación dará como resultado la exclusión de toda la ubicación del análisis. Se requieren 4 vecinos como mínimo para rellenar los bins vacíos utilizando el valor medio de los vecinos espaciales y un mínimo de 13 vecinos para rellenar los bins vacíos utilizando el valor medio de los vecinos de espacio-tiempo.
Al final del mensaje de salida se muestra información sobre la tendencia de datos general. Esta tendencia se basa en un análisis de la serie temporal no espacial. La pregunta general es: ¿aumentan o disminuyen con el tiempo los eventos representados mediante los puntos de entrada? Para obtener la respuesta, se analiza la cantidad de puntos de todas las ubicaciones en cada intervalo de período de tiempo como una serie temporal de valores de recuento utilizando la estadística de Mann-Kendall.
Dimensiones de bin para la agregación
En la mayoría de los casos sabe cómo definir las dimensiones de los bins del cubo y le recomendamos encarecidamente que piense en cuáles son las dimensiones apropiadas para las preguntas concretas para las que trata de obtener una respuesta. Por ejemplo, si trabaja con eventos de actos delictivos, puede decidir agregar puntos en bins de 400 metros o 0,25 millas porque es el tamaño de bloque de su ciudad. Si tiene datos que abarcan todo un año, quizás desee consultar las tendencias en términos de agregación mensual o semanal de eventos.
Parámetros predeterminados
En el caso improbable de que no tenga una buena justificación para un intervalo de período de tiempo o distancia concreto, puede dejar en blanco el parámetro de Intervalo de período de tiempo o Intervalo de distancia y dejar que sea la herramienta la que calcule los valores predeterminados.
La distancia predeterminada del bin se calcula de la siguiente manera:
- Determine la distancia del lado más largo de la extensión Entidades de entrada (extensión máxima).
- Así, la distancia del bin será el valor mayor de la máxima extensión dividida entre 100 o de un algoritmo basado en la distribución espacial de las Entidades de entrada.
El intervalo de período de tiempo predeterminado se basa en dos algoritmos diferentes que se utilizan para determinar la cantidad y al ancho óptimos de los intervalos de períodos de tiempo. El resultado numérico mínimo obtenido de estos algoritmos, superior a diez, se utiliza para la cantidad predeterminada de intervalos de períodos de tiempo. Si los dos resultados numéricos son inferiores a diez, la cantidad predeterminada de intervalos de períodos de tiempo será diez.
Alineación de período de tiempo
Alineación de períodos de tiempo es un parámetro muy importante a tener en cuenta al agregar los datos en un cubo de espacio-tiempo porque determina dónde empieza y termina la agregación. Veamos un ejemplo.
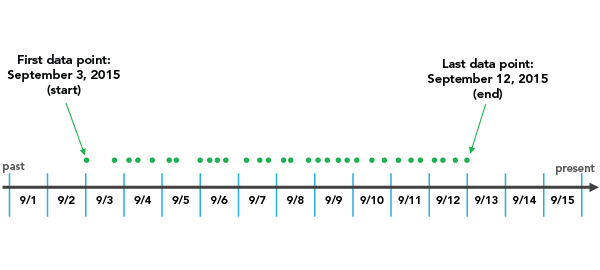
Tiempo final
Si se elige una END_TIME de Hora de fin con un Intervalo de período de tiempo de 3 días, por ejemplo, la creación de bins se iniciará en el último punto de datos e irá hacia atrás en incrementos de 3 días hasta que todos los puntos de datos queden dentro de un período de tiempo.
Es importante tener en cuenta que, según el Intervalo de periodo de tiempo elegido, es posible crear un periodo de tiempo al principio del cubo de espacio-tiempo que no contenga datos en todo el periodo de tiempo. En el ejemplo de arriba, puedee verse que el 1/9 y el 2/9 están incluidos en el primer intervalo de tiempo aunque no hay datos hasta el 3/9. Estos días vacíos forman parte del periodo de tiempo, pero no tienen datos asociados. Esto puede sesgar los resultados porque parecerá que el período de tiempo sesgado temporalmente tiene menos puntos de forma significativa que el resto de períodos, lo cual es, realmente, un resultado artificial debido a la forma de agregación. El informe indica si hay un sesgo temporal en el primer o el último paso. En este caso, 2 de los 3 días del primer periodo de tiempo no contienen datos, así que el sesgo temporal sería del 66 %.
END_TIME es la opción predeterminada de Alineación de período de tiempo porque muchos análisis se centran en lo que ha sucedido más recientemente, así que es preferible poner este sesgo hacia el principio del cubo. Otra solución, que elimina totalmente el sesgo temporal, sería proporcionar datos divididos uniformemente entre el Intervalo de período de tiempo de modo que no haya períodos de tiempo sesgados. Esto se puede hacer creando un conjunto de selección de los datos en los que se excluya la parte del dataset de puntos que queda fuera del período de tiempo que se desea que sea el primero. En este ejemplo, seleccionar todos los datos excepto los que quedan antes del 4/9 resolvería el problema. El informe muestra la duración del primer período y el último período y esta información se puede utilizar para determinar por dónde realizar el corte.
También es importante tener en cuenta que si, en el proceso de retroceder en el tiempo, el bin último queda exactamente en el primer punto de datos que sirve como su inicio, este punto de datos final no se incluirá en ese bin. Esto se debe a que con una END_TIME de Hora de fin, cada bin incluye la última fecha de un bin determinado y se extiende hacia atrás hasta la primera fecha de ese bin pero no la incluye. Así pues, en este caso sería necesario un bin agregado para garantizar la inclusión del primer punto.
Hora de inicio
Si se elige una START_TIME de Hora de inicio con un Intervalo de período de tiempo de 3 días, por ejemplo, la creación de bins se iniciará en el primer punto de datos y avanzará en incrementos de 3 días hasta que el último punto de datos quede dentro del último período de tiempo.
Es importante tener en cuenta algunas cosas. Una es que con una START_TIME de Hora de inicio, según el Intervalo de período de tiempo que elija, será posible crear un período de tiempo al final del cubo de espacio-tiempo que no contenga datos en todo el período de tiempo. En el ejemplo de arriba, puedee verse que el 13/9 y el 14/9 están incluidos en el último intervalo de tiempo aunque no hay datos después del 12/9. Estos días vacíos forman parte del periodo de tiempo, pero no tienen datos asociados. Esto puede sesgar los resultados porque parecerá que el período de tiempo sesgado temporalmente tiene menos puntos de forma significativa que el resto de períodos, lo cual es, realmente, un resultado artificial debido a la forma de agregación. El informe indica si hay un sesgo temporal en el primer o el último paso. En este caso, 2 de los 3 días del último periodo de tiempo no contienen datos, así que el sesgo temporal sería del 66 %. Esto es especialmente problemático si elegimos una START_TIME de Hora de inicio porque los análisis que se centran en los datos más recientes pueden verse afectados de forma importante. La solución sería proporcionar datos divididos uniformemente por el Intervalo de períodos de tiempo para que no hubiese períodos de tiempo sesgados. Esto se puede hacer creando un conjunto de selección de los datos en los que se excluya la parte del dataset de puntos que queda fuera del período de tiempo que se desea que sea el último. En este ejemplo, seleccionar todos los datos excepto los que quedan después del 11/9 resolvería el problema. También podría elegir recortar 2 días desde el principio del dataset, lo que también llevaría a que los datos quedaran distribuidos de manera uniforme dentro de los periodos de tiempo. El informe muestra la duración del primer período y el último período y esta información se puede utilizar para determinar por dónde realizar el corte.
También es importante tener en cuenta que si, en el proceso de avanzar en el tiempo, el último período de tiempo queda exactamente en el último punto de datos que sirve como su fin, este punto de datos final no se incluirá en ese bin. Esto se debe a que, con una START_TIME de Hora de inicio, cada bin incluye la primera fecha de un bin determinado y se extiende hacia delante hasta la última fecha de ese bin pero no la incluye. Así pues, en este caso sería necesario agregar un bin para garantizar la inclusión del último punto.
Tiempo de referencia
Una REFERENCE_TIME de Tiempo de referencia le permite garantizar que una fecha específica sea el inicio o el fin de uno de los períodos de tiempo del cubo.
Al elegir un REFERENCE_TIME que queda después de la extensión del dataset, en el último punto de datos, o en el centro del dataset, se tratará como el último punto de datos de un período de tiempo y todos los demás bins a cada lado se crearán utilizando una Alineación de períodos de tiempo hasta que todos los datos queden cubiertos, tal como se ilustra a continuación.
Al elegir un REFERENCE_TIME que queda antes de la extensión del dataset o en el primer punto de datos, se tratará como el primer punto de datos de un período de tiempo y todos los demás períodos de tiempo a cada lado se crearán utilizando una START_TIME de Hora de inicio hasta que todos los datos queden cubiertos, tal como se ilustra a continuación.
Tenga en cuenta que al elegir un REFERENCE_TIME antes o después de la extensión de los datos podría dar lugar a la creación de bins vacíos o parcialmente vacíos, lo cual puede introducir un sesgo en el análisis.
Cubos de plantilla
Utilizar un Cubo de plantilla permite utilizar una extensión espacial y un Intervalo de períodos de tiempo coherentes mientras se analizan distintos datasets. Por ejemplo, se puede usar el cubo de espacio-tiempo del último año como Cubo de plantilla después de adquirir datos del año próximo y esto garantiza la coherencia en la extensión espacial y el Intervalo de períodos de tiempo utilizados, a la vez que permite extender el cubo para abarcar datos nuevos. También se puede usar el cubo de espacio tiempo para un tipo de incidente como Cubo de plantilla para analizar otro tipo de incidente con el fin de garantizar que los resultados de los análisis se puedan comparar.
Elegir un Cubo de plantilla afecta a la Alineación de períodos de tiempo. Veamos algunos ejemplos. Al elegir un Cubo de plantilla que queda antes o después del intervalo de tiempo de las Entidades de entrada, se agregarán períodos de tiempo hasta que todos los datos queden cubiertos por un período de tiempo, utilizando la Alineación de períodos de tiempo del
Cubo de plantilla. El cubo de espacio-tiempo que resulta tiene cubos vacíos allí donde el Cubo de plantilla no se solape con las Entidades de entrada en el tiempo. Esto puede introducir un sesgo en los resultados de los análisis. Si el Cubo de plantillase solapa con las Entidades de entrada, el cubo de espacio-tiempo que resulta abarcará la extensión temporal del Cubo de plantilla y se extenderá hasta que todas lasEntidades de entrada queden cubiertas, utilizando la Alineación de períodos de tiempo del
Cubo de plantilla. La ilustración siguiente muestra los cubos de plantilla en color azul y los cubos de espacio-tiempo resultantes en color naranja.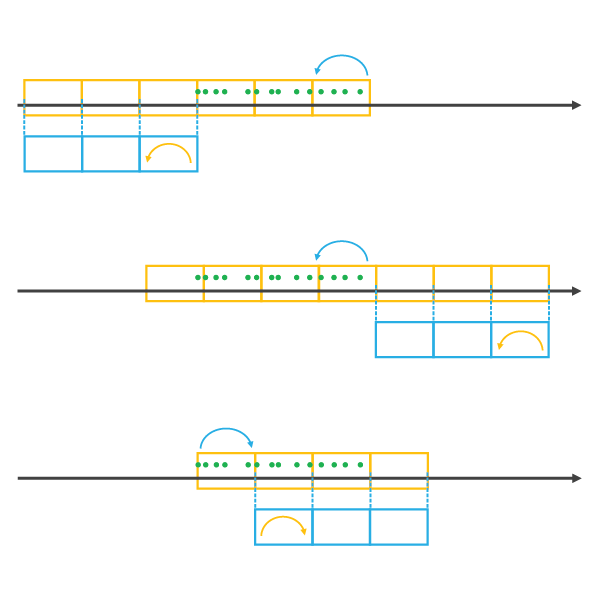
Es importante tener en cuenta que, al crear un nuevo cubo de espacio-tiempo utilizando un Cubo de plantilla, la extensión temporal del Cubo de plantilla se amplía hasta cubrir todos los datos. Esto permite utilizar el cubo del año pasado para crear un cubo nuevo que incluya los datos del año pasado y los de este año. La extensión espacial del Cubo de plantilla se trata de forma distinta. Todos los datos que queden fuera de la extensión espacial del Cubo de plantilla se omiten en el análisis. El Cubo de plantilla y el cubo de espacio-tiempo resultante tienen exactamente la misma extensión espacial. Los únicos cambios que se pueden producir en la extensión espacial están allí donde las ubicaciones que anteriormente no tenían datos pasan a tener datos al aparecer entidades nuevas que no estaban presentes cuando se creó el Cubo de plantilla.
Análisis de tendencia
La prueba de la tendencia de Mann-Kendall se realiza en todas las ubicaciones con datos como una prueba de serie temporal de bin independiente. La estadística de Mann-Kendall es un análisis de la correlación de la clasificación del recuento o el valor de los bins y su secuencia temporal. Se compara el valor de bin del primer período de tiempo con el valor de bin del segundo. Si el primero es menor que el segundo, el resultado será +1. Si el primero es mayor que el segundo, el resultado será -1. Si los dos valores son idénticos, el resultado es cero. Se suma el resultado de cada par de períodos de tiempo comparados. La suma prevista es cero, lo que indica que no se ha detectado ninguna tendencia en los valores en el tiempo. De acuerdo con la varianza de los valores en la serie temporal de los bins, el número de empates y el número de períodos de tiempo, se compara la suma obtenida con la suma prevista (cero) para determinar si la diferencia es significativa o no desde el punto de vista estadístico. La tendencia de la serie temporal de cada bin se registra como una puntuación z y un valor P. Un valor P bajo indica que la tendencia es significativa desde el punto de vista estadístico. El signo asociado a la puntuación z determina si se trata de una tendencia al alza de los valores de los bins (puntuación z positiva) o de una tendencia a la baja de los valores de los bins (puntuación z negativa). En Visualización del cubo de espacio-tiempo se incluyen estrategias para visualizar los resultados de las tendencias.

Recursos adicionales
La creación, la visualización y el análisis del cubo de espacio-tiempo utilizan el software netCDF desarrollado por UCAR/Unidata. Puede obtener más información sobre el proyecto de Unidata y Network Common Data Form (NetCDF) aquí.
Optimización del ancho del bin en el histograma
- Shimazaki H. and Shinomoto S., A method for selecting the bin size of a time histogram in Neural Computation (2007) Vol. 19(6), 1503–1527.
- Terrell, G. y Scott, D., Oversmoothed Nonparametric Density Estimates. Journal of the American Statistical Association (1985) Vol. 80(389), 209-214.
- Online Statistics Education: A Multimedia Course of Study (http://onlinestatbook.com/). Project leader: David M. Lane, Rice University (chapter 2, "Graphing Distributions, Histograms").
Prueba de tendencia de Mann Kendall
- Hamed, K. H., Exact distribution of the Mann-Kendall trend test statistic for persistent data in Journal of Hydrology (2009), 86–94.
- Kendall, M. G., Gibbons, J. D., Rank correlation methods, fifth ed., (1990) Griffin, London.
- Mann, H. B., Nonparametric tests against trend in Econometrica (1945) Vol. 13, 245–259.