L'outil Créer un cube spatio-temporel prend des entités ponctuelles horodatées et les structure en un cube de données netCDF en agrégeant les points en bins spatio-temporels. Les points de chaque groupe sont comptabilisés, les statistiques Champ de récapitulation sont calculées et la tendance temporelle des valeurs de groupes pour chaque emplacement est mesurée à l'aide de la statistique de Mann-Kendall. Vous pouvez utiliser cet outil pour créer le cube en entrée nécessaire pour l'exploration approfondie des modèles spatio-temporels, mais il permet également d'examiner des tendances de séries chronologiques dans votre zone d'étude.
Interprétation des résultats
La sortie produite par cet outil est une représentation netCDF de vos points en entrée. Vous pouvez visualiser en 2D ou 3D les données de total de points de cube à l'aide d'ArcGIS Pro. Outre le fichier netCDF, des messages récapitulant les dimensions du cube spatio-temporel et son contenu apparaissent dans la fenêtre Résultats. Cliquez avec le bouton droit sur l'entrée Messages dans la fenêtre Résultats et sélectionnez Afficher pour consulter les résultats dans une boîte de dialogue intitulée Message.

La structure du cube doit comporter des lignes, des colonnes et des intervalles temporels. Si vous multipliez le nombre de lignes par le nombre de colonnes par le nombre d'intervalles temporels, vous obtiendrez le nombre total de bins dans le cube. Les lignes et les colonnes déterminent l'étendue spatiale du cube, alors que les intervalles temporels déterminent l'étendue temporelle.

Pour la plupart des analyses, seuls les emplacements comportant des données pendant au moins un intervalle temporel seront inclus dans l'analyse, mais ils seront analysés pour tous les intervalles temporels. Lors de la comptabilisation des points, un nombre nul est supposé pour les groupes ne contenant aucun point, mais l'emplacement associé a présenté au moins un point pendant au moins un intervalle temporel. Des informations concernant le pourcentage de zéros associés aux emplacements comportant des données pendant au moins un intervalle temporel apparaissent dans les messages pour signaler une faible densité. Lors du calcul des valeurs des champs de récapitulation, le paramètre Remplir les groupes vides avec détermine le mode de remplissage des groupes sans point. Si des groupes ne peuvent pas être remplis en fonction des critères d'estimation, l'emplacement entier sera exclus de l'analyse. Un minimum de 4 voisins est nécessaire pour remplir des groupes vides à l'aide de la valeur moyenne des voisins spatiaux, et un minimum de 13 voisins est nécessaire pour remplir des groupes vides à l'aide de la valeur moyenne de voisins spatio-temporels.
A la fin du message de sortie figurent des informations sur la Tendance globale des données. Cette tendance repose sur une analyse de série chronologique aspatiale. La réponse fournie est globale. Est-ce que les événements représentés par les points en entrée augmentent ou diminuent au fil du temps ? Pour obtenir la réponse, le nombre de points pour tous les emplacements de chaque intervalle temporel est analysé sous la forme d'une série chronologique de valeurs numériques à l'aide de la statistique de Mann-Kendall.
Dimensions des groupes à agréger
Dans la plupart des cas, vous saurez comment définir les dimensions des groupes de cubes, mais nous vous recommandons de choisir des dimensions adaptées aux questions pour lesquelles vous souhaitez obtenir une réponse. Si vous observez, par exemple, des incidents criminels, vous pouvez agréger des points dans des groupes de 400 mètres (ou 0,25 mile), car il s'agit de la taille de votre îlot urbain. En présence de données couvrant une année entière, vous pouvez observer des tendances en matière d'agrégation d'événements sur une base mensuelle ou hebdomadaire.
Paramètres par défaut
Si, exceptionnellement, vous ne pouvez pas justifier un intervalle temporel ou un intervalle de distance spécifique, vous pouvez ne pas indiquer de valeur pour les options Intervalle temporel ou Intervalle de distance et laisser l'outil calculer pour vous les valeurs par défaut.
La distance du bin par défaut est calculée comme suit :
- Déterminez la distance du côté le plus long de l'étendue Entités en entrée (étendue maximale).
- La distance du groupe est alors la valeur la plus importante de l'étendue maximale divisée par 100 ou celle d'un algorithme basé sur la distribution spatiale des entités en entrée.
L'intervalle temporel par défaut est basé sur deux algorithmes différents permettant de déterminer le nombre et la largeur maximum des intervalles temporels. Le résultat numérique minimum de ces algorithmes, supérieur à dix, permet d'indiquer le nombre par défaut d'intervalles temporels. Lorsque les deux résultats numériques sont inférieurs à dix, le nombre par défaut d'intervalles temporels correspond à dix.
Alignement d'intervalle temporel
Il est important de considérer le paramètre Alignement d'intervalle temporel lors de l'agrégation de vos données en un cube spatio-temporel, car il détermine le début et la fin de l'agrégation. Examinons un exemple.
Exemple de données du paramètre 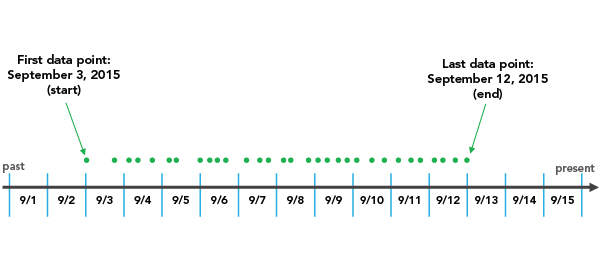
Heure de fin
Si vous choisissez END_TIME Alignement d'intervalle temporel avec une valeur d'Intervalle temporel de 3 jours par exemple, la classification commencera avec le dernier point de données et reviendra en arrière par incréments de 3 jours jusqu'à ce que tous les points de données soient compris dans un intervalle temporel.
Il est important de noter que, selon l' intervalle temporel que vous choisissez, il est possible de créer une phase temporelle au début du cube spatio-temporel qui ne comprend aucune donnée dans toute la période temporelle. Dans l'exemple ci-dessus, vous remarquerez que le 9/1 et le 9/2 sont inclus dans la première phase temporelle même si aucune donnée n'est présente jusqu'au 9/3. Ces jours vides font partie de la phase temporelle, mais aucune donnée ne leur est associée. Ceci peut déformer vos résultats, car la phase déformée temporellement semble comporter beaucoup moins de points que les autres phases temporelles, ce qui est en réalité un résultat artificiel du schéma d'agrégation. Le rapport indique si une déformation temporelle a lieu dans la première ou la dernière phase temporelle. Dans ce cas, 2 des 3 jours dans la première phase temporelle ne comportent aucune donnée, de sorte que la déformation temporelle est de 66 %.
END_TIME est l'option par défaut du paramètre Alignement d'intervalle temporel, car de nombreuses analyses se concentrent sur ce qui s'est produit le plus récemment. Il est ainsi préférable de placer cette déformation vers le début du cube. Une autre solution permettant de supprimer toute déformation temporelle, consiste à fournir des données qui sont divisées avec régularité en fonction de l'Intervalle temporel pour qu'aucune période temporelle ne soit déformée. Pour ce faire, vous pouvez créer un jeu de sélection des données qui exclut la partie du jeu de données ponctuelles qui se trouve en dehors de ce que vous souhaitez insérer dans la première période temporelle. Dans cet exemple, la résolution consiste à sélectionner toutes les données à l'exception de celles situées avant le 9/4. Le rapport affiche la période de la première et de la dernière phase temporelle et ces informations peuvent servir à déterminer où placer la limite.
Il est également important de noter que si, lors d'un retour arrière dans le passé, le groupe final coïncide exactement avec le premier point de données comme point de début, ce point de données final ne sera pas inclus dans ce groupe. En effet, avec un paramètre END_TIME Alignement d'intervalle temporel, chaque groupe inclut la dernière date dans un groupe donné, revient à la première date de ce groupe, mais ne l'inclut pas dans ce groupe. Par conséquent, dans ce cas, un groupe supplémentaire doit être ajouté pour garantir l'inclusion du premier point de données.
Heure de début
Si vous choisissez START_TIME Alignement d'intervalle temporel avec une valeur d'Intervalle temporel de 3 jours par exemple, la classification commencera au premier point de données et reviendra en arrière par incréments de 3 jours jusqu'à ce que le dernier point de données soit compris dans l'intervalle temporel final.
Il est important de noter quelques points. Le premier est qu'avec un paramètre START_TIME Alignement d'intervalle temporel, selon l'Intervalle temporel que vous choisissez, il est possible de créer un intervalle temporel à la fin du cube spatio-temporel qui ne comprend pas de données dans toute la période temporelle. Dans l'exemple ci-dessus, vous remarquerez que le 9/13 et le 9/14 sont inclus dans la dernière phase temporelle même si aucune donnée n'est présente après le 9/12. Ces jours vides font partie de la phase temporelle, mais aucune donnée ne leur est associée. Ceci peut déformer vos résultats, car la phase déformée temporellement semble comporter beaucoup moins de points que les autres phases temporelles, ce qui est en réalité un résultat artificiel du schéma d'agrégation. Le rapport indique si une déformation temporelle a lieu dans la première ou la dernière phase temporelle. Dans ce cas, 2 des 3 jours dans la dernière phase temporelle ne comportent aucune donnée, de sorte que la déformation temporelle est de 66 %. Ceci est particulièrement problématique lorsque vous choisissez un paramètre START_TIME Alignement d'intervalle temporel, car les analyses qui se concentrent sur les données les plus récentes peuvent être considérablement affectées. La solution consiste à fournir des données qui sont divisées avec régularité par l'Intervalle temporel afin qu'aucune période temporelle ne soit déformée. Pour ce faire, vous pouvez créer un jeu de sélection des données qui exclut la partie du jeu de données ponctuelles qui se trouve en dehors de ce que vous souhaitez insérer dans la dernière période temporelle. Dans cet exemple, la résolution consiste à sélectionner toutes les données à l'exception de celles situées après le 9/11. Vous pouvez également supprimer 2 jours au début du jeu de données, ce qui permet également de répartir les données équitablement au sein des intervalles temporels. Le rapport affiche la période de la première et de la dernière phase temporelle et ces informations peuvent servir à déterminer où placer la limite.
Il est également important de noter que si, lors d'un bond vers le futur, la phase temporelle finale coïncide exactement avec le dernier point de données comme point de fin, ce point de données final ne sera pas inclus dans ce groupe. En effet, avec un paramètre START_TIME Alignement d'intervalle temporel, chaque groupe inclut la première date dans un groupe donné, accède à la dernière date de ce groupe, mais ne l'inclut pas. Par conséquent, dans ce cas, un groupe supplémentaire doit être ajouté pour garantir l'inclusion du dernier point de données.
Référence temporelle
Un paramètre REFERENCE_TIME Alignement d'intervalle temporel permet de vous assurer qu'une date précise marque le début ou la fin d'un des intervalles temporels du cube.
Lorsque vous choisissez une REFERENCE_TIME qui tombe après l'étendue du jeu de données, au dernier point de données ou au milieu du jeu de données, elle est traitée comme le dernier point de données d'un intervalle temporel et tous les autres groupes d'un côté ou de l'autre sont créés à l'aide d'un paramètre Alignement d'intervalle temporel jusqu'à ce que toutes les données soient couvertes, comme cela est illustré ci-dessous.
Lorsque vous choisissez une REFERENCE_TIME qui tombe avant l'étendue du jeu de données ou au premier point de données, elle est traitée comme le premier point de données d'un intervalle temporel et tous les autres intervalles temporels d'un côté ou de l'autre sont créés à l'aide d'un paramètre START_TIME Alignement d'intervalle temporel jusqu'à ce que toutes les données soient couvertes, comme cela est illustré ci-dessous.
Notez que le choix d'une REFERENCE_TIME avant ou après l'étendue de vos données risque d'entraîner la création de groupes vides ou partiellement vides, ce qui peut fausser votre analyse.
Cubes modèles
L'utilisation d'un cube modèle vous permet d'utiliser une étendue spatiale et un intervalle temporel cohérents lors de l'analyse de différents jeux de données. Vous pouvez par exemple utiliser le cube spatio-temporel de l'année dernière comme cube modèle après avoir capturé les données de l'année suivante. Vous utilisez ainsi une étendue spatiale et un intervalle temporel cohérents tout en permettant au cube d'accueillir de nouvelles données. Vous pouvez également utiliser le cube spatio-temporel d'un type d'incident comme cube modèle pour analyser un autre type d'incident, afin d'assurer la validité de la comparaison des résultats d'analyse.
Le choix d'un cube modèle a des implications pour l'alignement d'intervalle temporel. Examinons quelques exemples. Lorsque vous choisissez un cube modèle qui a lieu avant ou après la période temporelle des entités en entrée, des phases temporelles sont ajoutées jusqu'à ce que toutes les données soient couvertes par une phase temporelle, à l'aide de l'alignement d'intervalle temporel du
cube modèle. Le cube spatio-temporel ainsi obtenu comporte des cubes vides lorsque le cube modèle n'a pas été temporellement superposé aux entités en entrée. Ceci peut déformer les résultats de l'analyse. Si le cube modèlese superpose aux entités en entrée, le cube spatio-temporel obtenu couvre l'étendue temporelle du cube modèle et s'étend jusqu'à ce que toutes lesentités en entrée soient couvertes, à l'aide de l'alignement d'intervalle temporel du
cube modèle. L'illustration ci-dessous présente les cubes modèles en bleu et les cubes spatio-temporels obtenus en orange.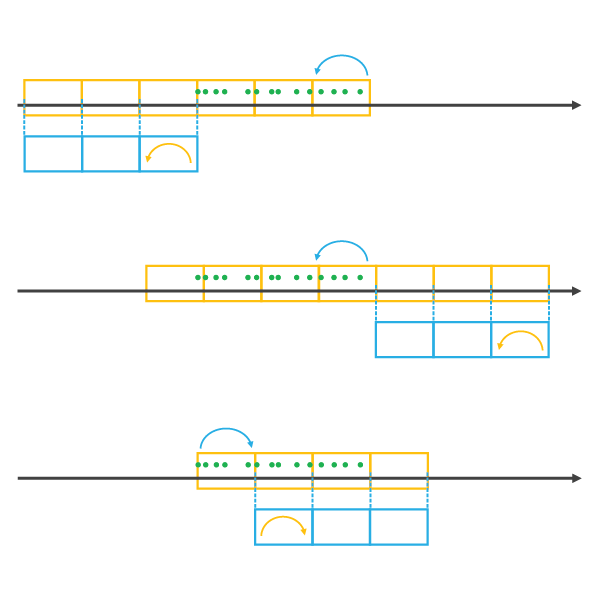
Il est important de noter que lorsque vous créez un nouveau cube spatio-temporel à l'aide d'un cube modèle, l'étendue temporelle du cube modèle est développée pour couvrir toutes les données. Ceci vous permet d'utiliser le cube de l'année précédente pour créer un nouveau cube qui comprend à la fois les données de l'année passée et celles de cette année. L'étendue spatiale du cube modèle est traitée différemment. Les données qui ne font pas partie de l'étendue spatiale du cube modèle sont supprimées de l'analyse. Le cube modèle et le cube spatio-temporel obtenu ont des étendues spatiales identiques. Les seules modifications susceptibles de se produire se situent au sein de l'étendue spatiale où des emplacements qui ne comportaient auparavant aucune donnée peuvent devenir des emplacements avec des données si de nouvelles entités qui n'étaient pas présentes au moment de la création du cube modèle sont apparues.
Analyse des tendances
Le test de tendance de Mann-Kendall est exécuté à chaque emplacement comprenant des données, sous la forme d'un test de série chronologique de bins. La statistique de Mann-Kendall est une analyse de corrélation de classement pour la valeur ou le total des groupes et leur ordre chronologique. La valeur des groupes de la première période est comparée à celle de la deuxième période. Si la première valeur est inférieure à la deuxième, le résultat est une valeur +1. Si la première valeur est supérieure à la deuxième, le résultat est une valeur -1. Si les deux valeurs sont égales, le résultat est nul. Le résultat de la comparaison de chaque paire de périodes est récapitulé. La somme attendue est égale à zéro pour indiquer que les valeurs ne font l'objet d'aucune tendance au fil du temps. Selon la variance des valeurs des séries chronologiques de groupes, le nombre de liens et le nombre de périodes, la somme observée est comparée à la somme attendue (zéro) pour déterminer si la différence est statistiquement significative ou non. La tendance de chaque série chronologique de bin est enregistrée sous la forme d'un score z et d'une valeur p. Une valeur p faible indique que la tendance est statistiquement significative. Le signe associé au score z détermine si la tendance indique une augmentation des valeurs de groupes (score z positif) ou une diminution des valeurs de groupes (score z négatif). Reportez-vous à la rubrique Visualisation du cube spatio-temporel pour savoir comment consulter les résultats des tendances.

Ressources supplémentaires
Histogram bin-width optimization
- Shimazaki H. and Shinomoto S., A method for selecting the bin size of a time histogram in Neural Computation (2007) Vol. 19(6), 1503–1527.
- Online Statistics Education: A Multimedia Course of Study (http://onlinestatbook.com/). Project leader: David M. Lane, Rice University (chapter 2, "Graphing Distributions, Histograms").
Mann-Kendall trend test
- Hamed, K. H., Exact distribution of the Mann-Kendall trend test statistic for persistent data in Journal of Hydrology (2009), 86–94.
- Kendall, M. G., Gibbons, J. D., Rank correlation methods, fifth ed., (1990) Griffin, London.
- Mann, H. B., Nonparametric tests against trend in Econometrica (1945) Vol. 13, 245–259.