Краткая информация
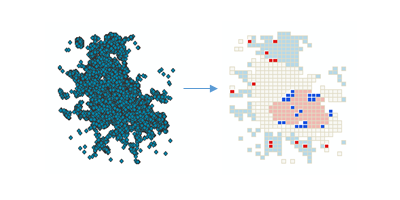
Приведенный набор точек инцидентов или взвешенных объектов (точек или полигонов) создает карту статистически значимых горячих и холодных точек, а также пространственных выбросов на основе статистического показателя Anselin Локальный индекс Морана I. При этом выполняется оценка характеристик класса входных объектов для получения оптимальных результатов.
Подробнее о том, как работает Оптимизированный анализ выбросов
Иллюстрация
Использование
Инструмент выявляет статистически значимые кластеры высоких значений (горячие точки) и низких значений (холодные точки), а также выбросы высоких и низких значений в ваших данных. Он автоматически агрегирует случайные данные, выбирает подходящий масштаб анализа и выполняет корректировку для множественного тестирования и пространственной зависимости. Этот инструмент обрабатывает ваши данные, чтобы определить настройки, которые помогут получить оптимальные результаты анализа кластеров и выбросов. Если вам необходим полный контроль над данными настройками, используйте инструмент Анализ кластеров и выбросов.
Вычисленные настройки, используемые для получения оптимальных результатов анализа кластеров и выбросов, выводятся в окне Результаты. Связанные рабочие процессы и алгоритмы описаны в разделе Как работает Оптимизированный анализ выбросов.
Инструмент создает новый Выходной класс объектов с новыми атрибутами, включающими локальный индекс I Морана (LMiIndex), z-оценку, псевдо p-значение и тип кластера/выбросов (COType) для каждого объекта во Входном классе объектов. Он также содержит поле (NNeighbors) в которое записывается для каждого объекта число соседних объектов, включенных в вычисление.
Поле COType указывает статистически значимые кластеры высоких и низких значений (HH и LL), а также высокие и низкие выбросы (HL и LH), скорректированные для множественного тестирования и пространственной зависимости при помощи метода коррекции Уровень ложно положительных результатов (FDR).
Z-оценки и р-значения являются измерениями статистической значимости, которая определяет, можно ли отклонить нулевую гипотезу. В действительности, они показывают, насколько очевидное сходство (пространственная кластеризация) или несходство (пространственные выбросы) являются чем-то большим, нежели случайное распределение. P-значения и z-оценки в Выходном классе пространственных объектов не отражают коррекцию FDR (False Discovery Rate). Дополнительные сведения о z-оценке и p-значениях см. в разделе Что такое z-оценка? Что такое p-значение?
Высокое положительное значение z-оценки для объекта свидетельствует, что окружающие объекты имеют схожие значения (либо низкие, либо высокие). Поле COType в Выходном классе объектов будет содержать значение HH для статистически значимого кластера с высокими значениями и LL для статистически значимого кластера с низкими значениями.
Малое отрицательное значение z-оценки (например, менее -3,96) для объекта свидетельствует о статистической значимости пространственных выбросов в данных. Поле COType в Выходном классе объектов будет указывать, имеет ли объект высокое значение и окружен объектами с низкими значениями(HL) или имеет низкое значение и окружен объектами с высокими значениями (LH).
В поле COType всегда указываются статистические значимые кластеры и выбросы на основании коррекции FDR с уровнем достоверности 95%. Только статистически значимые объекты имеют значения в поле COType.
Когда Входной класс объектов не имеет проекции (т.е. когда координаты заданы в градусах, минутах и секундах), или когда в качестве выходной системы координат задана Географическая система координат, расстояния будут рассчитываться с помощью хордовых измерений. Измерения хордовых расстояний применяются постольку, поскольку они могут быть быстро вычислены и дают очень хорошие оценки истинных геодезических расстояний, по крайней мере, для точек, расстояние между которыми в пределах порядка тридцати градусов. Хордовые расстояния основаны на эллипсоиде вращения. Если взять две любые точки на поверхности Земли, то хордовым расстоянием между ними будет длина прямой линии, проходящей через трехмерное тело Земли и соединяющей эти две точки. Хордовые расстояния выражаются в метрах.
Входными объектами могут быть точки или полигоны. Для полигонов требуется Поле анализа.
Если Вы предоставляете Поле анализа, то оно должно содержать разные значения. Для математических расчетов этой статистики требуется, чтобы анализируемые переменные обладали некоторой вариабельностью; например, анализ не будет выполняться, если все входящие значения равны 1.
С Полем анализа этот инструмент подходит для всех данных (точки и полигоны), в том числе для выборочных данных. В действительности, этот инструмент эффективен и надежен даже в случаях, когда число объектов очень большое. Когда объектов много, инструмент получает больше информации для вычисления точных и надежных результатов. Когда объектов мало, инструмент по-прежнему будет работать, чтобы получить точные и надежные результаты, но у него будет меньше информации, с которой он может работать.
С точечными данными вам иногда может понадобиться анализ значений данных по каждому из точечных объектов, и следовательно, вы будете использовать Поле анализа. В других случаях вам будет нужно лишь получить оценку пространственных структурных закономерностей (кластеризацию) местоположений точек или инцидентов точек. Решение вопроса о том, добавлять ли Поле анализа или нет, зависит от исследуемой вами задачи.
- Анализ точечных объектов с Полем анализа позволит вам получить ответ на такие вопросы, как: где сконцентрированы высокие и низкие значения?
- Выбранное поле анализа может представлять следующее:
- Количество (например, число ДТП на перекрестках)
- Показатели (например, безработица в городах, где каждый город показан точечным объектом)
- Средние (например, среднее значение результатов тестов по математике, проведенных во всех школах)
- Индексы (например, оценка уровня потребительской удовлетворенности автодилерами по всей стране)
- Анализ точечных объектов без добавления Поля анализа позволит вам определить места статистически значимой интенсивной или невысокой концентрации точек. Такой тип анализа поможет вам найти ответ на такие вопросы, как: В каком месте имеется много точек? В каком месте очень мало точек?
Если вы не будете использовать Поле анализа, инструмент соберет все ваши точки для их подсчета и использования в качестве поля анализа. Есть три возможных схемы агрегации:
- Для COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS и COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS, вычисляется подходящий размер ячейки полигона, который используется для создания сети сетевых или гексагональных полигонов над точками инцидентов и вычисления точек в каждой ячейке полигона. Если не существует векторного слоя Ограничивающие полигоны, определяющие возможное расположение инцидентов, то ячейки сетки с нулевым количеством точек удаляются, и анализируются только оставшиеся ячейки. При наличии векторного слоя ограничивающих полигонов сохраняются и анализируются все ячейки внутри ограничивающих полигонов. Количество точек для каждой полигональной ячейки используется в качестве поля анализа.
- ДляCOUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS и COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS необходимо задать векторный слой Полигоны для агрегирования инцидентов по количеству. Инциденты точек, попадающие внутрь каждого полигона, будут посчитаны, и эти полигоны со связанным количеством инцидентов будут затем проанализированы. COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS является подходящей стратегией агрегации, когда точки связаны с административными единицами, такими как участки, округа или школьные районы. Вы также можете использовать эту опцию, если вы хотите, чтобы изучаемая область оставалась одной и той же во время множественных анализов, чтобы воспользоваться преимуществом сравнения.
- Для SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS вычисляется расстояние замыкания, которое используется для агрегирования ближайших точек инцидентов. Каждой агрегированной точке присваивается количество, отражающее число инцидентов, которые были замкнуты друг с другом. Агрегированные точки затем анализируются, при этом количество инцидентов используется в качестве поля анализа. Опция SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS является подходящей стратегией агрегации, когда у вас есть много совпадающих или почти совпадающих точек, и вы хотите сохранить аспекты пространственной структурной закономерности исходных точечных данных. Во многих случаях вы можете захотеть использовать опции SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS и COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS, чтобы узнать, результаты какой из них наилучшим образом отражают пространственную структурную схему исходных точечных данных. Решения с использованием регулярной или гексагональной сетки могут искусственным образом разделить кластеры точечных инцидентов, но выходные данные при этом могут быть проще для интерпретации для некоторых пользователей, чем взвешенные выходные точечные данные.
Когда вы выбираете опциюCOUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS или COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS для Метода агрегирования данных инцидентов, вы можете дополнительно указать векторный слой Ограничивающие полигоны, определяющие возможное расположение инцидентов. Когда не предоставлено никаких ограничивающих полигонов, инструмент не может узнать, должно ли расположение без инцидента иметь значение 0, указывающее, что инцидент возможен, но не произошел, или расположение должно быть удалено из анализа, поскольку инциденты никогда не происходят в данном расположении. Соответственно, если не существует ни одного ограничивающего полигона, то для анализа берутся только те ячейки, которые содержат как минимум один инцидент. Если такое поведение вам не подходит, вы можете предоставить векторный слой Ограничивающие полигоны, определяющие возможное расположение инцидентов, чтобы убедиться, что все берутся все расположения внутри ограничивающих полигонов. Сетевые или гексагональные ячейки, не имеющие внутренних инцидентов, получат значение количества инцидентов, равное нулю.
Любые инциденты, не попадающие в Ограничивающие полигоны, определяющие возможное расположение инцидентов или в Полигоны для агрегирования инцидентов в количество, будут исключены из анализа.
Параметр Выполнение трансформации определяет количество перестановок, используемых при анализе. Выбор числа перестановок является компромиссом между точностью и временем обработки. Увеличение числа перестановок повышает точность, поскольку увеличивается диапазон возможных значений для вычисления псевдо p.
Перестановки используются для определения вероятности нахождения актуального пространственного распределения анализируемых значений. Для каждой перестановки, значения, окружающие каждый объект, перераспределяются в случайном порядке, затем вычисляется значение локального индекса Морана I. Результат референсного распределения значений затем сравнивается с наблюдаемым индексом Морана I для определения вероятного нахождения наблюдаемого значения в случайном распределении. По умолчанию используется 199 перестановок; однако распределение случайной выборки улучшается при увеличении числа перестановок, что повышает точность псевдо p-значений.
Инструмент вычислит оптимальный масштаб анализа на основе характеристик ваших данных, но вы можете настроить масштаб анализа, задав параметр Диапазон расстояний в разделе Опции переопределения. Для объекты, у которых нет соседей в пределах указанного расстояния Диапазон расстояний увеличивается таким образом, чтобы обнаружить хотя бы один соседний объект для включение в вычисления.
Вместо использования оптимальных по умолчанию настроек размера ячейки сетки и масштаба анализа, можно воспользоваться Опциями переопределения для установки Размера ячейки или Диапазона расстояния для анализа.
Опция Размер ячейки позволяет установить размер ячейки сетки, используемой для агрегирования ваших точечных данных. Например, можно использовать сетку с ячейками размером 50 на 50 метров. Если агрегация выполняется по гексагональной сетке, Размер ячейки определяет высоту каждого шестиугольника, а ширина полученных шестиугольников будет равняться 2 высотам, деленным на квадратный корень из 3.

Вам необходимо использовать инструменты Углубленного анализа пространственно-временных закономерностей или инструмент Построить матрицу пространственных весов совместно с инструментом Анализ кластеров и выбросов, если вы хотите идентифицировать кластеры и выбросы на основе пространственно-временного совпадения. Подробная информация о пространственно-временно кластерном анализе содержится в разделах Углубленный анализ пространственно-временных закономерностей или Пространственно-временной кластерный анализ.
-
Слои карты можно использовать для определения Входного класса объектов. Если в слое есть выборка, только выбранные объекты будут включены в анализ.
-
Слой Выходных объектов автоматически добавляется в таблицу содержания с методом отображения по умолчанию, в соответствии со значениями поля COType. Метод отображения определяется файлом слоя в <ArcGIS>\Desktop10.x\ArcToolbox\Templates\Layers. Метод отображения по умолчанию, если это необходимо, можно применить заново путем импорта символов слоя шаблона.
Синтаксис
OptimizedOutlierAnalysis_stats (Input_Features, Output_Features, {Analysis_Field}, {Incident_Data_Aggregation_Method}, {Bounding_Polygons_Defining_Where_Incidents_Are_Possible}, {Polygons_For_Aggregating_Incidents_Into_Counts}, {Performance_Adjustment}, {Cell_Size}, {Distance_Band})| Параметр | Объяснение | Тип данных |
Input_Features | Точечный или полигональный класс объектов, для которых будет выполняться анализ кластеров и выбросов. | Feature Layer |
Output_Features | Выходной класс объектов для представления полей с результатами. | Feature Class |
Analysis_Field (Дополнительный) | Числовое поле (количество инцидентов, тяжести преступления, тестовые оценки и т.д.), которое должно быть оценено. | Field |
Incident_Data_Aggregation_Method (Дополнительный) | Метод агрегирования, используемый для создания объектов с весами для анализа из данных точек инцидентов.
| String |
Bounding_Polygons_Defining_Where_Incidents_Are_Possible (Дополнительный) | Полигональный класс пространственных объектов, который определяет, где могут встретиться Input_Features инцидента. | Feature Layer |
Polygons_For_Aggregating_Incidents_Into_Counts (Дополнительный) | Полигоны, которые будут использоваться для агрегирования Input_Features инцидентов, чтобы рассчитать число инцидентов для каждого полигонального объекта. | Feature Layer |
Performance_Adjustment (Дополнительный) | Произвольное базовое распределения для анализа создается с использованием перестановок. Выбор числа перестановок является компромиссом между точностью и временем обработки. Выберите предпочтительные для вас скорость и точность. Для более значимых и точных результатов требуется больше времени.
| String |
Cell_Size (Дополнительный) | Размер ячейки сетки, используемой для агрегирования Input_Features. При агрегации в гексагональную сетку, это расстояние используется в качестве высоты для построения гексагональных полигонов. Этот инструмент поддерживает только футы, мили, метры и километры. | Linear Unit |
Distance_Band (Дополнительный) | Пространственный экстент окрестности анализа. Это значение определяет, какие объекты будут проанализированы вместе, чтобы оценить локальную кластеризацию. Этот инструмент поддерживает только футы, мили, метры и километры. | Linear Unit |
Пример кода
OptimizedOutlierAnalysis, пример 1 (окно Python)
Следующий скрипт окна Python демонстрирует, как использовать инструмент OptimizedOutlierAnalysis.
import arcpy
arcpy.env.workspace = r"C:\OOA"
arcpy.OptimizedOutlierAnalysis_stats("911Count.shp", "911OptimizedOutlier.shp", "#", "SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS", "#", "#", "BALANCED_499", "#", "#")
OptimizedOutlierAnalysis, пример 2 (автономный скрипт Python)
Следующий автономный Python скрипт демонстрирует, как использовать инструмент OptimizedOutlierAnalysis.
# Analyze the spatial distribution of 911 calls in a metropolitan area
# Import system modules
import arcpy
# Set property to overwrite existing output, by default
arcpy.env.overwriteOutput = True
# Local variables...
workspace = r"C:\OOA\data.gdb"
try:
# Set the current workspace (to avoid having to specify the full path to the feature classes each time)
arcpy.env.workspace = workspace
# Create a polygon that defines where incidents are possible
# Process: Minimum Bounding Geometry of 911 call data
arcpy.MinimumBoundingGeometry_management("Calls911", "Calls911_MBG", "CONVEX_HULL", "ALL",
"#", "NO_MBG_FIELDS")
# Optimized Outlier Analysis of 911 call data using fishnet aggregation method with a bounding polygon of 911 call data
# Process: Optimized Outlier Analysis
ooa = arcpy.OptimizedOutlierAnalysis_stats("Calls911", "Calls911_ohsaFishnet", "#", "COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS",
"Calls911_MBG", "#", "BALANCED_499", , "#", "#")
except arcpy.ExecuteError:
# If any error occurred when running the tool, print the messages
print(arcpy.GetMessages())
Параметры среды
- Выходная система координат
- Географические преобразования
- Текущая рабочая область
- Временная рабочая область
- Полноценные имена полей
- Выходные данные содержат M-значения
- Разрешение M
- Допуск M
- Выходные данные содержат Z значения
- Выходное Z значение по умолчанию
- Разрешение Z
- Допуск Z
- Разрешение XY
- Допуск XY
- Генератор случайных чисел
Информация о лицензиях
- ArcGIS Desktop Basic: Да
- ArcGIS Desktop Standard: Да
- ArcGIS Desktop Advanced: Да
Связанные разделы
- Моделирование пространственных отношений
- Что такое z-оценка? Что такое p-значение?
- Пространственные веса
- Обзор группы инструментов Картографирование кластеров
- Пространственная автокорреляция (Глобальный индекс Морана I)
- Как работает инструмент Оптимизированный анализ выбросов
- Анализ кластеров и выбросов (Anselin Локальный индекс Морана I)
- Анализ горячих точек (Getis-Ord Gi*)
- Оптимизированный анализ горячих точек