サマリー
インシデント ポイントまたは重み付きフィーチャ (ポイントまたはポリゴン) に基づいて、Anselin Local Moran's I 統計を使用し、統計的に有意なホット スポット、コールド スポット、および空間的な外れ値のマップを作成します。最適な結果を得るために、入力フィーチャクラスの特性が評価されます。
図
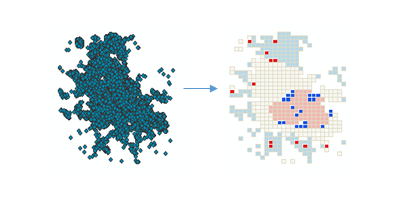
使用法
このツールは、統計的に有意な高い値および低い値の空間クラスター (ホット スポットとコールド スポット) と、データセット内で高い/低い外れ値を特定します。自動的にインシデント データが集約され、適切な分析のスケールが決定され、多重検定と空間依存性の両方に対して補正されます。このツールは、最適なクラスター/外れ値分析結果を取得する設定を決めるために、データを調べます。これらの設定を完全に制御したい場合は、代わりに [クラスター/外れ値分析 (Cluster and Outlier Analysis)] ツールを使用してください。
最適なクラスター/外れ値分析結果を得るために使用された、計算された設定は、[結果] ウィンドウにレポートされます。関連するワークフローとアルゴリズムが、「最適化外れ値分析 (Optimized Outlier Analysis) の詳細」で説明されています。
このツールは、入力フィーチャクラスの各フィーチャの Local Moran's I インデックス (LMiIndex)、Z スコア、p 値、およびクラスター/外れ値タイプ (COType) を含む新しい出力フィーチャクラスを作成します。また、フィールド (NNeighbors) に各フィーチャが計算に使用した近隣数が含められています。
COType フィールドは、統計的に有意な高い/低いクラスター (HH と LL) および高い/低い外れ値 (HL と LH) を特定し、FDR (False Discovery Rate) 補正を使用して多重検定と空間依存性に対して修正されます。
Z スコアと p 値は、フィーチャごとに帰無仮説を棄却すべきかどうかを判断する統計的有意性の尺度です。実際、この尺度は、見かけの類似性 (高いまたは低い値の空間クラスター) や相違 (空間的な外れ値) が、ランダムな分布で期待されるよりも顕著であるかどうかを示しています。出力フィーチャクラスの Z スコア と p 値は、FDR (False Discovery Rate) 補正を反映しません。Z スコアと p 値の詳細については、「Z スコアと p 値」をご参照ください。
フィーチャの Z 値が高い正の値である場合は、周囲のフィーチャの値が同様である (高い値または低い値) ことを示しています。出力フィーチャクラスの COType フィールドは、高い値を持つ統計的に有意なクラスターの場合は HH になり、低い値を持つ統計的に有意なクラスターの場合は LL になります。
フィーチャの Z スコアが低い負の値 (-3.96 未満など) である場合は、統計的に有意な空間データの外れ値であることを示しています。出力フィーチャクラスの COType フィールドは、高い値を持つフィーチャが低い値を持つフィーチャに取り囲まれている場合は HL になり、低い値を持つフィーチャが高い値を持つフィーチャに取り囲まれている場合は LH になります。
COType フィールドは常に、FDR (False Discovery Rate) 補正された 95 % の信頼度で統計的に有意なクラスターおよび外れ値を示します。統計的に有意なフィーチャのみで、COType フィールドに値が含まれます。
[入力フィーチャクラス] が投影されていない場合 (つまり、座標が、度、分、および秒で与えられた場合)、または出力座標系が地理座標系に設定された場合、弦の測定値を使用して距離が計算されます。少なくとも互いに約 30°の範囲内のポイントに対して、素早く計算することができ、真の測地距離の非常に優れた推定値が得られるため、弦距離の測定値が使用されます。弦距離は、短回転楕円体に基づいています。地球の表面上の 2 点が与えられた場合、2 点間の弦の距離は、3 次元の地球内部を通過して 2 点を接続するラインの長さになります。弦距離は、メートル単位でレポートされます。
入力フィーチャとして、ポイントまたはポリゴンを指定できます。ポリゴンの場合、[分析フィールド] は必須です。
[分析フィールド] を指定する場合、さまざまな値を含める必要があります。この統計計算では、分析する変数に変異が存在する必要があります。たとえば、入力値がすべて 1 の場合、解は存在しません。
このツールは、[分析フィールド] で指定された、サンプリングされたデータを含むあらゆるデータ (ポイントまたはポリゴン) を適切に処理できます。実際、このツールは、オーバーサンプリングが存在する場合でも効果的であり、信頼できます。フィーチャの数が多い場合 (オーバーサンプリング)、ツールは、正確で信頼できる結果を計算するための多くの情報を得ることができます。フィーチャの数が少ない場合 (アンダーサンプリング) でも、ツールは、正確で信頼できる結果を生成するために、可能なことをすべて実行します。ただし、処理される情報は少なくなります。
ポイント データでは、各ポイント フィーチャに関連付けられたデータ値の解析に関心がある場合があります。その場合、[分析フィールド] を指定します。その他のケースでは、ポイントの位置またはポイント インシデントの空間パターン (クラスタリング) を評価することのみが必要になります。[分析フィールド] を指定するかどうかは、質問の内容によって変わります。
- [分析フィールド] を使用してポイント フィーチャを分析することで、「高い/低い値のクラスターはどこか」のような質問に答えることができます。
- 選択する分析フィールドは以下のいずれかを表します。
- 個数 (交差点での交通事故件数など)
- 比率 (都市の失業率など。ここで各都市は、ポイント フィーチャで表されます)
- 平均 (学校間のテスト スコアの平均計算など)
- インデックス (郡の車の販売代理店に関する顧客満足度など)
- [分析フィールド] がない場合にポイント フィーチャを分析することで、ポイントのクラスタリングが異常 (統計的に有意な程度) に密集しているかまばらな場所を識別できます。この種の分析は、「多くのポイントが存在する場所はどこか」、 「ポイントが非常に少ない場所はどこか」のような質問に答えることができます。
[分析フィールド] を指定しない場合、このツールは、分析フィールドとして使用するポイント数を得るために、ポイントを集約します。以下の 3 種類の集約方法を指定できます。
- COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS および COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS の場合、適切なポリゴン セルのサイズが計算され、フィッシュネットまたは六角形のポリゴンの作成に使用されます。これは、インシデント ポリゴン上に配置され、各ポリゴン セル内のポイント数が計算されます。[インシデント範囲境界ポリゴン] フィーチャ レイヤーを指定しない場合、ポイント数がゼロのセルが削除され、残りのセルのみが分析されます。境界ポリゴン フィーチャ レイヤーを指定した場合、境界ポリゴンに含まれるすべてのセルが保持されて、分析されます。各ポリゴン セルのポイント数は、分析フィールドとして使用されます。
- COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS および COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS の場合、[インシデント集約境界ポリゴン] フィーチャ レイヤーを指定する必要があります。各ポリゴンに含まれるポイント インシデント数が計算されます。関連するカウントを含めたこれらのポリゴンが、分析されます。COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS は、ポイントが行政地名 (地域、群、学区など) に関連する場合に適した集約方法です。比較操作を強化するために、複数の分析にまたがって分析範囲を固定したい場合にも、このオプションを使用できます。
- SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS の場合、スナップ距離が計算され、近傍のインシデント ポイントの集約に使用されます。集約された各ポイントには、一緒にスナップされたインシデントの数を反映するカウントが与えられます。次に、集約されたポイントは、インシデント数を分析フィールドとして使用して分析されます。SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS は、多くのポイントが同じ位置または近い位置にあり、元のポイント データの空間パターンの特徴を維持したい場合に適した集約方法です。多くの場合、SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS、COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS および COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS を試してみて、どちらの結果が元のポイント データの空間パターンをよく反映しているかを確認したほうがよいでしょう。フィッシュネットおよび六角形による方法は、ポイント インシデントのクラスターを人為的に分割しますが、人によっては、重み付きポイントの出力よりも、この出力の方が解釈しやすいことがあります。
インシデント データ集約方法として COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS または COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS を選択した場合、オプションで [インシデント範囲境界ポリゴン] フィーチャ レイヤーを指定できます。境界ポリゴンを指定しないと、ツールは、インシデントのない場所をゼロに設定して、インシデントが発生する可能性があるが発生していないことを示すべきかどうかを判断できず、インシデントが発生する可能性がない場所を分析から削除するべきかどうかを判断することもできません。その結果、境界ポリゴンを指定しない場合、1 つ以上のインシデントを含むセルのみが分析の対象として保持されます。このような動作を望まない場合は、境界ポリゴン内のすべての場所を確実に保持するように、[インシデント範囲境界ポリゴン] フィーチャ レイヤーを指定できます。インシデントを含まないフィッシュネットまたは六角形のセルには、インシデント数としてゼロが与えられます。
インシデント範囲境界ポリゴンにもインシデント集約境界ポリゴンにも含まれないインシデントは、すべて分析から除外されます。
[パフォーマンス調整] パラメーターは、分析に使用する順列の数を指定します。順列の数を選択する場合は、精度と処理時間の増加とのバランスを考慮します。順列の数を多くすると、疑似 p 値の範囲が広くなり、結果的に精度が上がります。
順列を使用すると、分析する値の実際の空間分布が検出される可能性がどれくらいあるかを判断できます。順列を実行するごとに、各フィーチャの周囲の近傍値がランダムに並べ替えられ、Local Moran's I 値が算出されます。この計算結果が値の基準分布になり、観測値がランダム分布の中から検出される確率を求めるために実際の観測対象の Moran's I と比較されます。順列の数はデフォルトで 199 に設定されていますが、順列の数を増やすと、ランダム標本分布が広範になり、これに伴って疑似 p 値の精度も上がります。
ツールはデータの特性に基づいて、最適な分析のスケールを計算します。または、[設定を上書き] の [距離バンド] パラメーターを使用して、分析のスケールを設定できます。この距離の近傍がないフィーチャの場合、各フィーチャが少なくとも 1 つの近傍を持つように [距離バンド] が延長されます。
グリッドのセル サイズと分析のスケールに最適なデフォルト値をツールで選択する代わりに、[設定を上書き] を使用して、解析の [セル サイズ] または [距離バンド] を設定できます。
[セル サイズ] オプションを使用すると、ポイント データの集約に使用されるグリッドのサイズを設定できます。たとえば、フィッシュネット グリッドの各セルを 50 x 50 メートルにしたりできます。六角形に集約している場合、[セル サイズ] は各六角形の高さになり、生成される六角形の幅は、高さの 2 倍を 3 の平方根で除算した値になります。

時空間ホット スポットを特定する場合は、[時空間パターン マイニング] ツールまたは、[空間ウェイト マトリックスの生成 (Generate Spatial Weights Matrix)] ツールおよび [クラスター/外れ値分析 (Cluster and Outlier Analysis)] ツールを使用する必要があります。時空間クラスター分析については、「時空間パターン マイニング」のドキュメントまたは「時空間クラスター分析」のトピックをご参照ください。
-
マップ レイヤーを使用して、入力フィーチャクラスを指定できます。解析対象として指定したレイヤーの中で何らかのフィーチャが選択されている場合、選択されているフィーチャだけが解析の対象となります。
-
出力フィーチャ レイヤーは自動的に [コンテンツ] ウィンドウに追加され、COType フィールドにはデフォルトのレンダリングが適用されます。レンダリングは、<ArcGIS>\Desktop10.x\ArcToolbox\Templates\Layers にあるレイヤー ファイルによって定義されます。必要に応じて、テンプレート レイヤー シンボルをインポートすれば、デフォルトのレンダリングを再適用できます。
構文
OptimizedOutlierAnalysis_stats (Input_Features, Output_Features, {Analysis_Field}, {Incident_Data_Aggregation_Method}, {Bounding_Polygons_Defining_Where_Incidents_Are_Possible}, {Polygons_For_Aggregating_Incidents_Into_Counts}, {Performance_Adjustment}, {Cell_Size}, {Distance_Band})| パラメーター | 説明 | データ タイプ |
Input_Features | クラスター/外れ値分析が実行されるポイント フィーチャクラスまたはポリゴン フィーチャクラス。 | Feature Layer |
Output_Features | 結果のフィールドを取得するための出力フィーチャクラス。 | Feature Class |
Analysis_Field (オプション) | 評価する数値フィールド (インシデント数、犯罪率、テストのスコアなど)。 | Field |
Incident_Data_Aggregation_Method (オプション) | インシデント ポイント データから分析するための重み付きフィーチャの作成に使用される集約方法。
| String |
Bounding_Polygons_Defining_Where_Incidents_Are_Possible (オプション) | インシデントInput_Featuresが発生する可能性のある場所を定義するポリゴン フィーチャクラス。 | Feature Layer |
Polygons_For_Aggregating_Incidents_Into_Counts (オプション) | ポリゴン フィーチャごとのインシデント数を取得するために、インシデントInput_Featuresの集計に使用されるポリゴン。 | Feature Layer |
Performance_Adjustment (オプション) | この分析は、基準分布を作成するために順列を利用します。順列の数を選択する場合は、精度と処理時間の増加とのバランスを考慮します。速度と精度の優先度を選択します。有効性と精度が高い結果ほど、計算に時間がかかります。
| String |
Cell_Size (オプション) | Input_Features の集約に使用されるグリッド セルのサイズ。六角形グリッドに集約している場合、この距離は、六角形ポリゴンを構築するための高さとして使用されます。 このツールでサポートされているのは、キロメートル、メートル、マイル、フィートのみです。 | Linear Unit |
Distance_Band (オプション) | 分析対象の近傍の空間範囲。この値は、ローカル クラスタリングを評価する場合に一緒に分析されるフィーチャを決定します。 このツールでサポートされているのは、キロメートル、メートル、マイル、フィートのみです。 | Linear Unit |
コードのサンプル
OptimizedOutlierAnalysis (最適化外れ値分析) の例 1 (Python ウィンドウ)
次の Python ウィンドウ スクリプトは、OptimizedOutlierAnalysis ツールの使用方法を示しています。
import arcpy
arcpy.env.workspace = r"C:\OOA"
arcpy.OptimizedOutlierAnalysis_stats("911Count.shp", "911OptimizedOutlier.shp", "#", "SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS", "#", "#", "BALANCED_499", "#", "#")
OptimizedOutlierAnalysis (最適化外れ値分析) の例 2 (スタンドアロン Python スクリプト)
次のスタンドアロン Python スクリプトは、OptimizedOutlierAnalysis (類似検索) ツールの使用方法を示しています。
# Analyze the spatial distribution of 911 calls in a metropolitan area
# Import system modules
import arcpy
# Set property to overwrite existing output, by default
arcpy.env.overwriteOutput = True
# Local variables...
workspace = r"C:\OOA\data.gdb"
try:
# Set the current workspace (to avoid having to specify the full path to the feature classes each time)
arcpy.env.workspace = workspace
# Create a polygon that defines where incidents are possible
# Process: Minimum Bounding Geometry of 911 call data
arcpy.MinimumBoundingGeometry_management("Calls911", "Calls911_MBG", "CONVEX_HULL", "ALL",
"#", "NO_MBG_FIELDS")
# Optimized Outlier Analysis of 911 call data using fishnet aggregation method with a bounding polygon of 911 call data
# Process: Optimized Outlier Analysis
ooa = arcpy.OptimizedOutlierAnalysis_stats("Calls911", "Calls911_ohsaFishnet", "#", "COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS",
"Calls911_MBG", "#", "BALANCED_499", , "#", "#")
except arcpy.ExecuteError:
# If any error occurred when running the tool, print the messages
print(arcpy.GetMessages())
環境
ライセンス情報
- ArcGIS Desktop Basic: はい
- ArcGIS Desktop Standard: はい
- ArcGIS Desktop Advanced: はい
関連トピック
- 空間関係のモデリング
- Z スコアと p 値
- 空間ウェイト
- クラスター分析のマッピング ツールセットの概要
- 空間的自己相関分析 (Spatial Autocorrelation (Global Moran's I))
- 最適化外れ値分析 (Optimized Outlier Analysis) の詳細
- クラスター/外れ値分析 (Cluster and Outlier Analysis (Anselin Local Moran's I))
- ホット スポット分析 (Hot Spot Analysis (Getis-Ord Gi*))
- 最適化ホット スポット分析 (Optimized Hot Spot Analysis)