Resumen
Dados unos puntos de incidentes o unas entidades ponderadas (puntos o polígonos), crea un mapa de puntos calientes, puntos fríos y valores atípicos espaciales estadísticamente significativos utilizando la estadística de I Anselin local de Moran. Evalúa las características de la clase de entidad de entrada para producir resultados óptimos.
Más información sobre cómo funciona el Análisis optimizado de valores atípicos
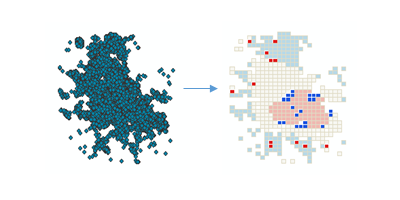
Ilustración
Uso
Esta herramienta identifica clusters espaciales estadísticamente significativos de valores altos (puntos calientes) y bajos (puntos fríos), así como valores atípicos altos y bajos dentro del dataset. Agrega automáticamente datos de incidentes, identifica una escala de análisis apropiada y corrige tanto las diversas pruebas como la dependencia espacial. Esta herramienta interroga los datos para determinar la configuración que producirá resultados óptimos en el análisis de clusters y valores atípicos. Si desea un control total sobre esta configuración, utilice en su lugar la herramienta Análisis de cluster y de valor atípico.
La configuración calculada que se utiliza para producir resultados óptimos en el análisis de cluster y de valor atípico se notifica en la ventana Resultados. Los flujos de trabajo y algoritmos asociados se explican en Cómo funciona el Análisis optimizado de valores atípicos.
Esta herramienta crea una nueva Clase de entidad de salida con un índice I de Moran local (LMiIndex), puntuación z, pseudo valor P y tipo de cluster/valor atípico (COType) para cada entidad en la Clase de entidad de entrada. También incluye un campo (NNeighbors) con la cantidad de vecinos que cada entidad incluyó en sus cálculos.
El campo COType identifica clusters altos y bajos estadísticamente significativos (HH and LL) as well as high and low outliers (HL and LH), corrected for multiple testing and spatial dependence using the False Discovery Rate (FDR) correction method.
Las puntuaciones z y los valores p son medidas de significancia estadística que indican si se rechazará la hipótesis nula, entidad por entidad. En efecto, indican si la aparente similitud (un clustering espacial de valores altos o bajos) o la falta de similitud (un valor atípico espacial) es más marcada de lo que se espera en una distribución aleatoria. La puntuación z y los valores p de la Clase de entidad de salida no reflejan ningún tipo de correcciones de FDR (Índice de descubrimientos falsos). Para obtener más información sobre las puntuaciones z y los valores P, consulte ¿Qué es una puntuación z? ¿Qué es un valor p?
Una puntuación z positiva alta para una entidad indica que las entidades circundantes tienen valores similares (ya sea valores altos o bajos). El campo COType en la Clase de entidad de salida será Alto para un cluster de valores altos estadísticamente significativo y Bajo para un cluster de valores bajos estadísticamente significativo.
Una puntuación z negativa baja (por ejemplo, inferior a -3,96) para una entidad indica un valor atípico de datos espacial estadísticamente significativo. El campo COType en la Clase de entidad de salida indicará si la entidad tiene un valor alto y está rodeada por entidades con valores bajos (Alto/bajo) o si la entidad tiene un valor bajo y está rodeada por entidades con valores altos (Bajo/alto).
El campo COType indicará siempre unos clusters y valores atípicos estadísticamente significativos basados en un nivel de confianza del 95 por ciento del Índice de descubrimientos falsos corregidos. Solamente las entidades estadísticamente significativas tienen valores para el campo COType.
Cuando la Clase de entidad de entrada no está proyectada (es decir, cuando las coordenadas se especifican en grados, minutos y segundos) o cuando el sistema de coordenadas de salida está establecido en un Sistema de coordenadas geográficas, las distancias se calculan mediante mediciones de cuerda. Las mediciones de distancia de cuerda se utilizan porque se pueden calcular rápidamente y proporcionar muy buenas estimaciones de verdaderas distancias geodésicas, al menos para los puntos separados unos treinta grados entre sí. Las distancias de cuerda se basan en un esferoide oblato. Dados dos puntos en la superficie de la Tierra, la distancia de cuerda entre ellos es la longitud de una línea, que atraviesa la Tierra tridimensional, para conectar estos dos puntos. Las distancias de cuerda se informan en metros.
Las Entidades de entrada pueden ser puntos o polígonos. Con polígonos, se requiere un Campo de análisis.
Si se proporciona un Campo de análisis, debe contener una variedad de valores. La operación matemática para esta estadística requiere cierta variación en la variable analizada; por ejemplo, no se puede resolver si todos los valores de entrada son 1.
Con un Campo de análisis, esta herramienta es apta para todos los datos (puntos o polígonos) que incluyan datos de muestreo. De hecho, esta herramienta es efectiva y fiable incluso cuando existe un exceso de muestreo. Cuando hay muchas entidades (exceso de muestreo), la herramienta tiene demasiada información para calcular resultados precisos y fiables. Cuando hay pocas entidades (falta de muestreo), la herramienta hará todo lo posible para generar resultados precisos y fiables, pero dispondrá de menos información con la que trabajar.
Con los datos de punto, en ocasiones le puede interesar analizar valores de datos asociados con cada entidad de puntos, y en consecuencia proporcionará un Campo de análisis. En otros casos, quizá solo le interese evaluar el patrón espacial (clustering) de las ubicaciones de puntos o incidentes de puntos. La decisión de proporcionar o no un Campo de análisis dependerá de la pregunta que se esté formulando.
- El análisis de entidades de puntos con un Campo de análisis le permite responder a preguntas del tipo: ¿Dónde se agrupan los valores altos y bajos?
- El campo de análisis seleccionado podría representar lo siguiente:
- Recuentos (como el número de accidentes de tráfico en las intersecciones de calles)
- Tasas (como desempleo urbano, en la que cada ciudad está representada por una entidad de punto)
- Medias (como la nota media en los exámenes de matemáticas entre escuelas)
- Índices (como el índice de satisfacción del consumidor para concesionarios de coches del país)
- Analizar entidades de puntos cuando no existe un Campo de análisis le permite identificar dónde se da un clustering de puntos inusualmente intensa o escasa (estadísticamente significativa). Este tipo de análisis responde a preguntas del tipo: ¿Dónde hay muchos puntos? ¿Dónde se encuentran pocos puntos?
Si no proporciona un Campo de análisis, la herramienta agregará los puntos para obtener recuentos de puntos que utilizará como un campo de análisis. Hay tres esquemas de agregación posibles:
- Para COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS y COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS, se calcula un tamaño de celda de polígono aproximado y se utiliza para crear una red de polígono de red o hexagonal que, a continuación, se coloca encima de los puntos del incidente y se cuentan los puntos que hay dentro de cada celda de polígono. Si no se proporciona una capa de entidades Polígonos de delimitación que definen dónde es posible que se produzcan incidentes, las celdas con cero puntos se eliminan y solo se analizan las celdas restantes. Cuando se proporciona una capa de entidad poligonal de delimitación, todas las celdas que quedan dentro de los polígonos de delimitación se conservan y analizan. Los recuentos de puntos para cada celda de polígono se usan como campo de análisis.
- Para COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS y COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS, debe proporcionar la capa de entidades Polígonos para agregar incidentes en recuentos. Se realizará el recuento de los incidentes de punto que caigan dentro de cada polígono y se analizarán estos polígonos con sus recuentos asociados. La opción COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS es una estrategia de agregación apropiada cuando los puntos se asocian a unidades administrativas como distritos, condados o distritos escolares. También puede usar esta opción si desea que el área de estudio permanezca fija en los diversos análisis para optimizar la realización de comparaciones.
- Para SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS, se calcula una distancia de alineación y se usa para agregar puntos de incidentes cercanos. A cada punto agregado se le otorga un recuento que refleja el número de incidentes que se alinearon juntos. A continuación, los puntos agregados se analizan con los recuentos de incidentes sirviendo como campo de análisis. La opción SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS es una estrategia de agregación apropiada cuando se tienen muchos puntos coincidentes, o prácticamente coincidentes, y se desea mantener aspectos del patrón espacial de los datos de puntos originales. En muchos casos le convendrá probar SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS, COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS y COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS para ver qué resultado refleja mejor el patrón espacial de los datos de puntos originales. Las soluciones de red y de hexágono pueden separar artificialmente clusters de incidentes de punto pero, para algunas personas, la interpretación de la salida puede ser más fácil que la salida de punto ponderado.
Cuando se selecciona COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS o COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS para el Método de agregación de datos de incidentes, puede proporcionar opcionalmente una capa de entidades Polígonos de delimitación que definen dónde es posible que se produzcan incidentes. Cuando no se proporcionan polígonos de delimitación, la herramienta no puede saber si una ubicación sin un incidente debe ser un cero para indicar que es posible un incidente en esa ubicación pero no se produjo, o si la ubicación debe eliminarse del análisis porque nunca se producirían incidentes en la misma. Por consiguiente, cuando no se proporcionan polígonos de delimitación, solo las celdas que tienen al menos un incidente se conservan para su análisis. Si no es este el comportamiento que desea, puede proporcionar una capa de entidades Polígonos de delimitación que definen dónde es posible que se produzcan incidentes para asegurarse de que se conserven todas las ubicaciones dentro de los polígonos de delimitación. Las celdas de red o de hexágono sin incidentes subyacentes recibirán un recuento cero de incidentes.
Los incidentes que caigan fuera de Polígonos de delimitación que definen dónde es posible que se produzcan incidentes o de Polígonos para agregar incidentes en recuentos se excluirán del análisis.
El parámetro Ajuste de rendimiento especifica cuántas permutaciones se utilizan en el análisis. Elegir el número de permutaciones es un equilibrio entre la precisión y un mayor tiempo de procesamiento. Al aumentar el número de permutaciones se incrementa la precisión porque aumenta el rango de posibles valores para el pseudo P.
Las permutaciones se utilizan para determinar la probabilidad de encontrar la distribución espacial real de los valores que está analizando. Para cada permutación, los valores de vecindad alrededor de cada entidad se reorganizan aleatoriamente y se calcula el valor I de Moran local. El resultado es una distribución de referencia de los valores que luego se comparan con el valor I de Moran real observado para determinar la probabilidad de que el valor observado pueda encontrarse en la distribución aleatoria. El valor predeterminado es de 199 permutaciones; no obstante, la distribución de la muestra aleatoria se ha mejorado con más permutaciones, lo que mejora la precisión del pseudo valor P.
La herramienta calculará la escala de análisis óptima basándose en las características de los datos o bien puede definir la escala del análisis mediante el parámetro Banda de distancia en la Configuración de invalidación. Para entidades que no tienen vecinos a esta distancia, la Banda de distancia se extiende para que cada entidad tenga al menos un vecino.
En lugar de dejar que la herramienta elija los valores predeterminados óptimos para el tamaño de celda de la cuadrícula y la escala del análisis, se puede utilizar la Configuración de invalidación para definir el Tamaño de celda o la Banda de distancia para el análisis.
La opción Tamaño de celda le permite definir el tamaño de la cuadrícula utilizado para agregar los datos de puntos. Por ejemplo, puede decidir que cada celda de la cuadrícula de red sea de 50 x 50 metros. Si va a agregar a hexágonos, el Tamaño de celda será la altura de cada hexágono y el ancho de los hexágonos resultantes será el doble de la altura dividido entre la raíz cuadrada de 3.

Debe usar las herramientas Minería de patrones en espacio-tiempo o las herramientas Generar matriz de ponderaciones espaciales y Análisis de cluster y de valor atípico si desea identificar puntos calientes de espacio-tiempo. Se proporciona más información acerca del análisis de clúster de espacio-tiempo en la documentación de Minería de patrones en espacio-tiempo o en el tema Análisis de clúster de espacio-tiempo.
-
Las capas del mapa se pueden utilizar para definir la Clase de entidad de entrada. Cuando se utiliza una capa con una selección, solo las entidades seleccionadas se incluyen en el análisis.
-
La capa Entidades de salida se agrega automáticamente a la tabla de contenido con la representación en pantalla predeterminada aplicada al campo COType. La representación está definida por un archivo de capas en <ArcGIS>\Desktop10.x\ArcToolbox\Templates\Layers. Puede volver a aplicar la representación predeterminada, de ser necesario, al importar la simbología de capa de plantilla.
Sintaxis
OptimizedOutlierAnalysis_stats (Input_Features, Output_Features, {Analysis_Field}, {Incident_Data_Aggregation_Method}, {Bounding_Polygons_Defining_Where_Incidents_Are_Possible}, {Polygons_For_Aggregating_Incidents_Into_Counts}, {Performance_Adjustment}, {Cell_Size}, {Distance_Band})| Parámetro | Explicación | Tipo de datos |
Input_Features | La clase de entidad poligonal o de puntos para la que se realizará el análisis de cluster y de valor atípico. | Feature Layer |
Output_Features | La clase de entidad de salida que recibirá los campos de resultados. | Feature Class |
Analysis_Field (Opcional) | El campo numérico (número de incidentes, índices de delincuencia, puntuaciones de exámenes, etc.) que se va a evaluar. | Field |
Incident_Data_Aggregation_Method (Opcional) | El método de agregación que se va a usar para crear entidades ponderadas para su análisis a partir de datos de puntos de incidentes.
| String |
Bounding_Polygons_Defining_Where_Incidents_Are_Possible (Opcional) | Clase de entidad poligonal que define dónde podrían producirse las Input_Features de incidentes. | Feature Layer |
Polygons_For_Aggregating_Incidents_Into_Counts (Opcional) | Polígonos que se usan para agregar las Input_Features de incidentes para obtener un recuento de incidentes para cada entidad poligonal. | Feature Layer |
Performance_Adjustment (Opcional) | Este análisis utiliza permutaciones para crear una distribución de referencias. Elegir el número de permutaciones es un equilibrio entre la precisión y un mayor tiempo de procesamiento. Elija su preferencia para la velocidad frente a precisión. Los resultados más sólidos y precisos tardan más en calcularse.
| String |
Cell_Size (Opcional) | El tamaño de las celdas de cuadrícula utilizado para agregar las Input_Features. Al agregar a una cuadrícula hexagonal, esta distancia se utiliza como la altura para construir los polígonos hexagonales. Esta herramienta solo admite kilómetros, metros, millas y pies. | Linear Unit |
Distance_Band (Opcional) | La extensión espacial de la vecindad de análisis. Este valor determina las entidades que se analizan conjuntamente para evaluar el clustering local. Esta herramienta solo admite kilómetros, metros, millas y pies. | Linear Unit |
Muestra de código
Ejemplo 1 de OptimizedOutlierAnalysis (ventana de Python)
La siguiente secuencia de comandos de la ventana de Python muestra cómo utilizar la herramienta OptimizedOutlierAnalysis.
import arcpy
arcpy.env.workspace = r"C:\OOA"
arcpy.OptimizedOutlierAnalysis_stats("911Count.shp", "911OptimizedOutlier.shp", "#", "SNAP_NEARBY_INCIDENTS_TO_CREATE_WEIGHTED_POINTS", "#", "#", "BALANCED_499", "#", "#")
Ejemplo 2 de OptimizedOutlierAnalysis (secuencia de comandos de Python independiente)
La siguiente secuencia de comandos de Python independiente muestra cómo utilizar la herramienta OptimizedOutlierAnalysis.
# Analyze the spatial distribution of 911 calls in a metropolitan area
# Import system modules
import arcpy
# Set property to overwrite existing output, by default
arcpy.env.overwriteOutput = True
# Local variables...
workspace = r"C:\OOA\data.gdb"
try:
# Set the current workspace (to avoid having to specify the full path to the feature classes each time)
arcpy.env.workspace = workspace
# Create a polygon that defines where incidents are possible
# Process: Minimum Bounding Geometry of 911 call data
arcpy.MinimumBoundingGeometry_management("Calls911", "Calls911_MBG", "CONVEX_HULL", "ALL",
"#", "NO_MBG_FIELDS")
# Optimized Outlier Analysis of 911 call data using fishnet aggregation method with a bounding polygon of 911 call data
# Process: Optimized Outlier Analysis
ooa = arcpy.OptimizedOutlierAnalysis_stats("Calls911", "Calls911_ohsaFishnet", "#", "COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS",
"Calls911_MBG", "#", "BALANCED_499", , "#", "#")
except arcpy.ExecuteError:
# If any error occurred when running the tool, print the messages
print(arcpy.GetMessages())
Entornos
- Sistema de coordenadas de salida
- Transformaciones geográficas
- Espacio de trabajo actual
- Espacio de trabajo temporal
- Nombres de campos calificados
- La salida tiene valores M
- Resolución M
- Tolerancia M
- La salida tiene valores Z
- Valor Z de salida predeterminado
- Resolución Z
- Tolerancia Z
- Resolución XY
- Tolerancia XY
- Generador de números aleatorios
Información sobre licencias
- ArcGIS Desktop Basic: Sí
- ArcGIS Desktop Standard: Sí
- ArcGIS Desktop Advanced: Sí
Temas relacionados
- Modelado de relaciones espaciales
- ¿Qué es una puntuación z? ¿Qué es un valor P?
- Ponderaciones espaciales
- Vista general del conjunto de herramientas Asignación de clusters
- Autocorrelación espacial (I de Moran)
- Cómo funciona el análisis de valores atípicos optimizado
- Análisis de cluster y de valor atípico (I Anselin local de Moran)
- Análisis de punto caliente (Gi* de Getis-Ord)
- Análisis de puntos calientes optimizado